Trailers15k Dataset

Trailers15k is a multi-label dataset containing 15,000 videos of movie trailers associated with 10 different classes that correspond to film genres. The videos were taken from YouTube and the labels from IMDb. We make Trailers15k available to the research community to support future work in video understanding.
An upgraded version of this dataset is Trailers12k.
Distribution
The number of the videos for each class is shown in the following plot. As can be appreciated the dataset is unbalanced, for example, there are three times more drama videos than animation videos.
The following plot shows the number of trailers with a given number of labels. The videos in the database are associated with up to three different genres.
Partition procedure
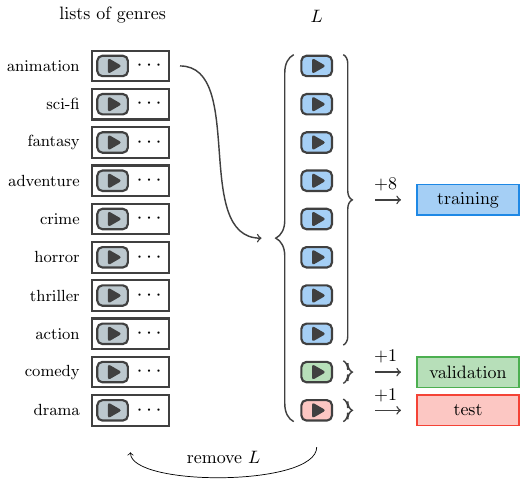
The partition of the database for training, validation and test sets was 80%, 10% and 10%, respectively. In order to create the partition that respect the original distribution of the genres the following procedure was used. For each genre, create a randomly ordered list with its corresponding videos. Take a sublist L of ten videos of the smallest list. Assign eight, one, and one videos to the training, validation and test set respectively. Remove each element of L from all the lists in which it appears. Continue with the next smallest list. Repeat until all lists are empty. The following image shows the procedure described.
The following plot show the distribution of videos by classes for the training, validation and test sets.
Download
Dataset is available on Zenodo.
-
Metadata.
trailers15k-mltc.csv(469K)- mid (1 col): movie id.
- genres (2-11 cols): binary labels.
- subset (12 col): training (0), validation (1), test (2).
-
Video trailer frame-level features (1 FPS) extracted with the Inception-v3 model.
train.zip(11G)valid.zip(11G)test.zip(11G)
Features Loading
Features are stored with
zarr. The next snippet loads features of one trailer.
import zarr
z = zarr.group(store=zarr.ZipStore('train.zip', mode='r'))
# get numpy array of tt0347149 mid
a = z['tt0347149']
a.shape, a.dtype
# ((96, 2048), dtype('float32'))
Code
The code to download and preprocess the dataset is available on a Bitbucket repository.
People
Contact
If you have any questions please do not hesitate to contact us.
Acknowledgements
This research was carried out thanks to the Program of Support for Research Projects and Technological Innovation (PAPIIT) of the UNAM IA104016 Generation of video summaries based on deep neural networks from beginning to end. I thank the DGAPA-UNAM for the scholarship received.
References
[1] B. Montalvo. Clasificación multi-etiqueta de videos cortos usando unidades recurrentes reguladas. Master’s thesis, Universidad Nacional Autónoma de México, Mexico, 2018 (in Spanish). [PDF]