Identificación de hablante (cont)
This is my voice, there are many like it, but this one is mine — This is my voice, Shane Koyczan
Revisión
El método presentado en la clase anterior
- Supone una distribución normal para los fenómenos
- Cuantifica un fenómeno particular
- Basada en una fórmula siguiendo esta específicación
Ejemplo
Fórmula
- $LR=\frac{\tau}{a\sigma} e^{\left[-\frac{(x-y)^2}{2a^2\sigma^2}\right]} e^{\left[-\frac{(w-\mu)^2}{2\tau^2} +\frac{(z-\mu)^2}{\tau^2} \right]} $
- $x$: Media dubitativa
- $y$: Media indubitada
- $\mu$: Media referencia
- $\sigma$: Desviación estándar de dubitativa e indubitada
- $\tau$: Desviación estándar referencia
- $z=(x+y)/2$
- $w=(mx+ny)/(m+n)$
- $m$: número de dubitativas
- $n$: número de indubitada
- $a=\sqrt{\frac1m + \frac1n}$
Lindley, D.V., 1977. A problem in forensic science. Biometrika 64/2, 207–213
Pero en realidad hay varias alternativas...
Tipos de características
- Auditivas: basados en escucha
- Lingüísticos: basados en fenómenos fonéticos/fonológicos
- Manuales: interpretables
- Automáticos: discriminativos
Rose, Phil. "Technical forensic speaker recognition: Evaluation, types and testing of evidence." Computer Speech & Language 20.2 (2006): 159-191.
Características auditivas
Nos sirve para analizar a las grabaciones
- ¿Las grabaciones son comparables?
- ¿Características de la referencia?
- Mientras tengamos un análisis informado, ejem.:
- Voz murmurada: en vietnamita no relevante, en inglés sí (con cuidado)
Rose, Phil. "Technical forensic speaker recognition: Evaluation, types and testing of evidence." Computer Speech & Language 20.2 (2006): 159-191.
Ejemplos: características lingüísticas
Otras vocales
- Segundo formante $F2$ y $F3$ (inglés, cantones)
- $F1$ se evita por susceptibilidad con el canal/medio
- Algunas limitaciones (cap. 11, Rose 2002)
Rose, Phil. Forensic speaker identification. CRC Press, 2003.
fuck$_{F1 F2 F3}$ y fucken$_{F1 F2 F3}$
- Fonemas /ɐ/
- Tres primeras formantes
Rose, Phil. Forensic speaker identification. CRC Press, 2003.
Ejemplo: $yeah$
- Secuencia de formantes
Rose, Phil. Forensic speaker identification. CRC Press, 2003.
Trayectorias de formantes en diptongo
- Diptongo $/ai/$ del inglés
- Se mide la pendiente (ángulo)
- Se supone una distribución normal sobre pendientes
Kinoshita, Y., & Osanai, T. (2006, December). Within speaker variation in diphthongal dynamics: What can we compare. In Proceedings of the 11th Australasian International Conference on Speech Science & Technology, Auckland, New Zealand. Australia: Australasian Speech Science & Technology Association, Canberra (pp. 112-117).
Trayectorias de formantes en diptongo
- Patrón-F y tonal de cantonés ($F1$-$F4$ y $F0$)
- Se calculan polinomios que representen las trayectorias
- Los coeficientes se usan para calcular $LR$
Likelihood-ratio forensic voice comparison using parametric representations of the formant trajectories of diphthongsa) Morrison, Geoffrey Stewart, The Journal of the Acoustical Society of America, 125, 2387-2397 (2009)
Trayectorias de formantes en diptongo
- Fonemas vocálico en contexto consonántico ($F2$ y $F3$)
- Un segmento se normaliza en tiempo
- Se calculan por cada punto en la trayectoria
- Se fusionan, en lugar de multiplicar, porque no son independientes
Likelihood-ratio forensic voice comparison using parametric representations of the formant trajectories of diphthongsa) Morrison, Geoffrey Stewart, The Journal of the Acoustical Society of America, 125, 2387-2397 (2009)
Aspectos suprasegmentales
- ??
Likelihood-ratio forensic voice comparison using parametric representations of the formant trajectories of diphthongsa) Morrison, Geoffrey Stewart, The Journal of the Acoustical Society of America, 125, 2387-2397 (2009)
En términos de característica fonéticas
- Long term F0
- Automático
LTF0
- Se enfoca a varias medidas de $F0$
- No importa el fenómeno fonético/fonológico
- Varios segundos
Varios $F0$
- No se asume una distribución normal
- Se usa kernel density estimation
Un poco de más matemáticas
- $LR=\frac {Ke^{ -\frac{(x-y)^2}{2a^2 \sigma^2}} \sum_{i=1}^{k} e^{-\frac{(m+n)(w-z_i)^2}{2\left[\sigma^2+(m+n)\tau^2\lambda^2 \right]}}} { \sum_{i=1}^{k} e^{-\frac{m(x-z_i)^2}{2(\sigma^2+m\tau^2\lambda^2)]}} \sum_{i=1}^{k} e^{-\frac{m(y-z_i)^2}{2(\sigma^2+n\tau^2\lambda^2)]}} } $
- donde $K=\frac {\sqrt{m+n}\sqrt{\sigma^2+m\tau^2\lambda^2}\sqrt{\sigma^2+n\tau^2\lambda^2}} {a\sigma\sqrt{mn}\sqrt{\left[ \sigma^2+(m+n)\tau^2 \lambda^2 \right]}} $
Rose, Phil. Forensic speaker identification. CRC Press, 2003.
Además
- $x$: Media dubitativa
- $y$: Media indubitada
- $\mu$: Media referencia
- $\sigma$: Desviación estándar de dubitativa e indubitada
- $\tau$: Desviación estándar referencia
- $\lambda$: factor de smoothing
- $m$: número de dubitativas
- $n$: número de indubitada
- $k$: número de núcleos
- $w=(mx+ny)/(m+n)$
- $a=\sqrt{\frac1m + \frac1n}$
Rose, Phil. Forensic speaker identification. CRC Press, 2003.
Automático
- ¿Por qué usar solo una característica?
- Usamos toda la información...
- ... okay no todos
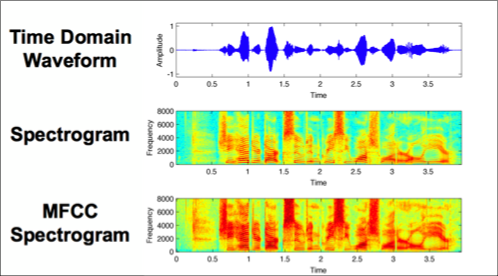
Representación/Compresión de la voz
Se comprime la señal en ventanas
- Mel: 40 valores
- MFCC: 13 valores
- LPC: 40 valores
Ejemplo
Modelos
Con la representación creamos modelos
- Mel: 40 valores
- MFCC: 13 valores
- LPC: 40 valores
Ejemplo 2D
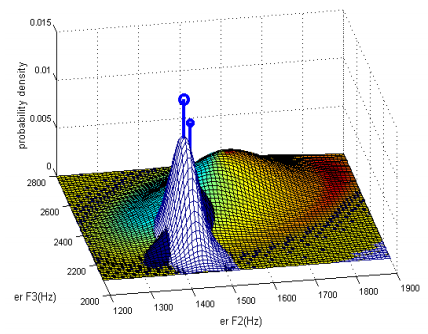
Rose, P. (2006) Catching criminals by their voice: Combining automatic and traditional methods for optimum performance in forensic speaker recognition.
Modelado
Gausian Mixture Models (GMM)
- Se modela como una mezcla de distribuciones Gaussinas
- $GMM_{dubitativa}$, $GMM_{indubitada}$ y $GMM_{referencia}$
Dos opciones
- A través de similitudes (4 tipos de grabaciones )
- Método directo (2 tipos de grabaciones)
Similitudes
Tres tipos de grabaciones
- Grabación dubitativa
- Se crean dos grupos de grabaciones indubitadas
- En el tiempo: grabaciones en el tiempo
- Control: grabaciones en un momento
- Grabación de referencia
Meuwly, Didier, and Andrzej Drygajlo. "Forensic speaker recognition based on a Bayesian framework and Gaussian Mixture Modelling (GMM)." 2001: A Speaker Odyssey-The Speaker Recognition Workshop. 2001.
Primer paso: variabilidad en fuente indubitada
- Se crea un modelo por cada grabación en el tiempo $GMM_{t}$
- Se evalúa $GMM_{t}(Control)$
Segundo paso: variabilidad con referencia
- Se crea un modelo por cada usuario $GMM_{u}$
- Se evalúa $GMM_{u}(Dubitativa)$
Tercer paso: Se calcula la evidencia
- Usando el primer $GMM_{t1}$
- Se evalúa $GMM_{t1}(Dubitativa)$
Cuarto paso: Se calcula la evidencia
- Similitud es $P(E|Var_{indubitada})$
- Tipicidad es $P(E|var_{referencia})$
Método directo
Tres tipos de grabaciones
- Grabación dubitativa
- Grabación indubitada
- Grabación de referencia
Meuwly, Didier, and Andrzej Drygajlo. "Forensic speaker recognition based on a Bayesian framework and Gaussian Mixture Modelling (GMM)." 2001: A Speaker Odyssey-The Speaker Recognition Workshop. 2001.
Primer paso
- Se crea un modelo con indubitativa $GMM_{i}$
- Se evalúa $GMM_{i}(Dubitativa)$
- Similaridad
Segundo paso
- Se crea un modelo con referencia $GMM_{R}$
- Se evalúa $GMM_{R}(Dubitativa)$
- Tipicidad
Tercer paso
- $LR=\frac{Similaridad}{Tipicidad}$
Nueva dirección
Aprendizaje profundo
Lee, Honglak, et al. "Unsupervised feature learning for audio classification using convolutional deep belief networks." Advances in neural information processing systems. 2009.
Problemas con LR
- Calidad y cantidad de grabaciones
- Variabilidad en referencia
- Una sola grabación
Joaquin Gonzalez-Rodriguez, Andrzej Drygajlo, Daniel Ramos-Castro, Marta Garcia-Gomar, Javier Ortega-Garcia, Robust estimation, interpretation and assessment of likelihood ratios in forensic speaker recognition, Computer Speech & Language, Volume 20, Issues 2–3, April–July 2006, Pages 331-355, ISSN 0885-2308

Identificación de hablante (cont.) by Ivan V. Meza Ruiz is licensed under a Creative Commons Reconocimiento 4.0 Internacional License.
Creado a partir de la obra en http://turing.iimas.unam.mx/~ivanvladimir/slides/fonologia_forense/identification_cont.html.