Regresión lineal y, sub y sobre ajuste
La metodología
datos
Head Size and Brain Weight, R.J. Gladstone
La línea como un modelo
Elementos de la línea
Como modelo
Espacio de hipótesis
Reformulando... (expandiendo \emph{x})
¿... pero por qué...?
Como operación de matrices
Pero podemos hacerlo mejor...
Pasando a $m$ dimensiones
Pero podemos hacerlo mejor...
Redefiniendo regresión lineal
Para un conjunto de $\boldsymbol{X}$ de $n$ datos en $\mathbb{R^m}$, de la forma $\boldsymbol{x}_{i=1}^n$ y para cual que agregamos un vector constante $x_{i0}=1$
Y para un conjunto de $y$ de $n$ puntos relacionados con $\boldsymbol{X}$ en posición.
Suponemos:
¿Qué dimensión tiene $W$?
Evaluación: Error cuadrado
¿Qué agregué de forma tramposa?
Más específico
Mucho más específicos
Optimización: búsqueda
Descenso por gradiente
Algunas funciones son fáciles

Tomado de Wikipedia
Algunas funciones son difíciles

Tomado de Wikipedia
Imaginemos

Recordemos
Derivando para dimensión $d$
Derivadas de las sumas
Derivada de potencias
Expandiendo sumatoria
Expandiendo sumatoria
Derivando elementos
Simplificando
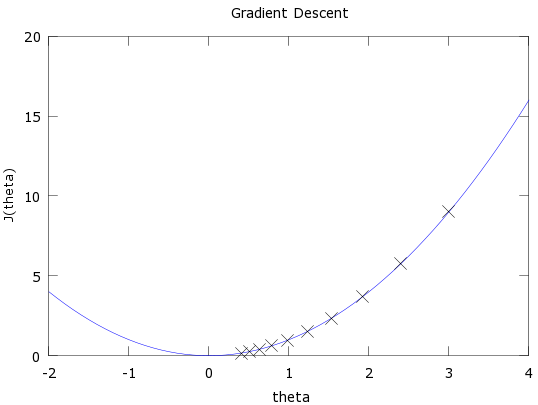
Tomado de Gradient Descent Derivation

Tomado de Wikipedia
¿Qué hay de $k$?

Tomado de CS231n
¿Pero con qué pesos comenzamos?
Como es aproximativo, no siempre tenemos el mismo modelo
¿Que tipo de errores tenemos?
Podemos pensar que nuestro espacio de hipótesis $\mathbb{H}$ es un espacio de expertos
Cada experto tiene desarrolló una experiencia propia con el problema, entonces difieren en como resolver el problema
¿Que tipo de errores cometen?
Se equivocan siempre de igual forma
Se equivocan por todos lados
Es decir
El experto tiene un sesgo ($Bias$)
El experto tiene varianza ($Var$)
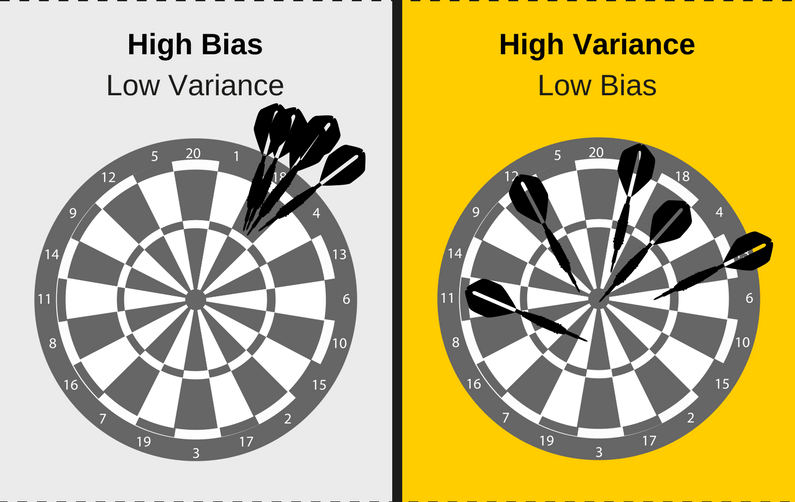
Tomado de WTF is the Bias-Variance Tradeoff?
Los errores son una combinación de ambos factores
Falta un tipo de error
Intrínsecos del problema ($\epsilon$)
¿Quien tiene la culpa del error?
¿El algoritmo o la hipótesis?
Valores esperados
Predicción esperada
Error cuadrático esperado
Sesgo
Es la diferencie entre la predicción esperada y el valor verdadero
¿Por qué es malas noticias para nosotros?
Varianza
Es la diferencia entre la predicción al cuadrado esperada y el cuadrado de la predicción esperada
Error cuadrático esperado
O en otras palabras
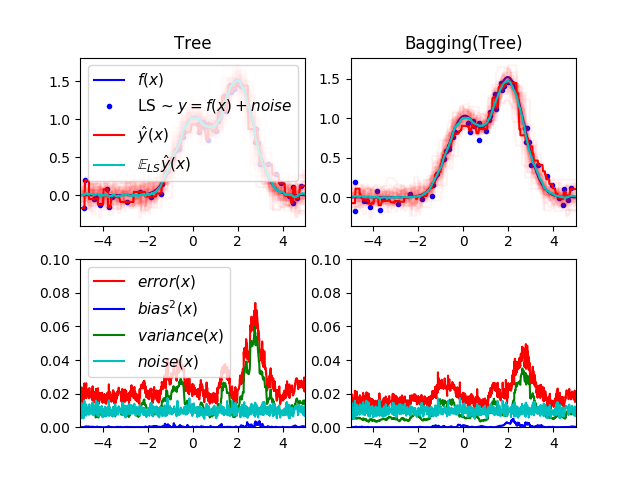
Tomado de Single estimator versus bagging: bias-variance decomposition
Compromiso entre sesgo y varianza
Modelos más sencillos, producen un alto sesgo
Modelos más complejos, producen un bajo sesgo
Modelos más sencillos, producen un baja varianza espacio $\mathbb{H}$ más grande
Modelos más complejos, producen un alta varianza espacio $\mathbb{H}$ más grande
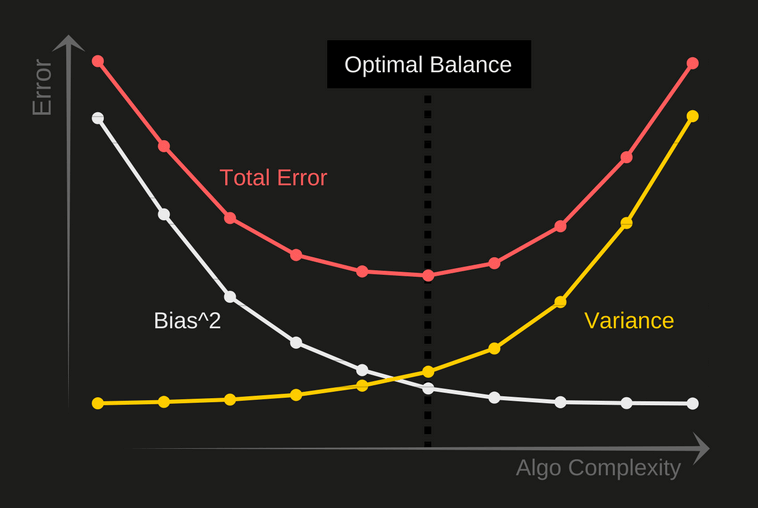
Tomado de WTF is the Bias-Variance Tradeoff?
Sub ajuste
Es cuando el modelo es muy simple que no es suficiente para modelar las relaciones de los datos de entrenamiento
Imaginen el modelo $y=c$
Sobre ajuste
Es cuando el modelo es muy complejo de tal forma que memoriza los datos de entrenamiento, lo único que modela es el ruido
Imaginen el modelo $f=g+\epsilon$
Ante nuevos datos falla más

Tomado de Underfitting vs. Overfitting

Regresión lineal y, sub y sobre ajusto by Ivan V. Meza Ruiz is licensed under a Creative Commons Reconocimiento 4.0 Internacional License.
Creado a partir de la obra en http://turing.iimas.unam.mx/~ivanvladimir/slides/rpyaa/02_regresión.html.