GNB, logistic regression, training
Naive Bayes discreta
Naive Bayes clasificación
Parámetros
¿Entradas continuas?
Tenemos que cambiar $p(X_i|Y)$, para modelar el comportamiento de $X_i$ dado una $Y$
Si $X_i$ es continuo, no es posible usar cuentas de su ocurrencia.
Una forma barata de representar la distribución Gaussiana
Distribución Gaussiana
$\mu$ es la media de la Gaussiana, y $\sigma$ la desviación estándar
Parámetros
Dos parámetros por característica, por número de salidas posibles, es decir $2mk$ donde $m$ es el número de características, y $k$ el número de clases
La media
Para una cantidad de $n$ datos podemos usar MLE
Donde $\delta$ es una función selector que regresa $1$ cuando el dato $k$ coincide con la clase $y_j$
La $\mu$ para la característica $i$ dada la clase $j$ es la suma de todos los valores $X_i$ dónde la salida fue la clase $y_j$
La desviación estándar
Para una cantidad de $n$ datos podemos usar MLE
Sin embargo se prefiere el estimador mínimo sin varianza sin sesgo (MVUE, siglas en inglés)
La $\sigma$ para la característica $i$ dada la clase $j$ es la suma de las diferencias al cuadrado del dato $X_i$ con $\mu_{ij}$ dónde la salida fue la clase $y_j$
Naive Bayes continua
Naive Bayes continua clasificación
¿Podemos usar un modelo como el de regresión lineal, para clasificar?
Función sigmoide logística
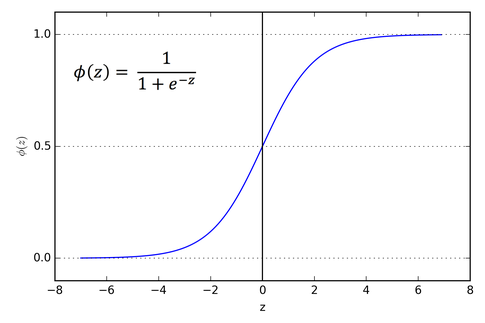
Clasificación con pesos
si $x=W^TX$ y $Y$ binaria
Ajustando los pesos
Una opción es hacerlo a través de la distribución Gaussiana
Si dividimos entre $P(X|1)P(1)$ al denominador y numerador
Si asumimos independencia entre las variables
Si asumimos $P(X_i|y)$ es una Gaussiana, y qué $\sigma_{i0}=\sigma_{i1}$
Regresando
Acomodando
y
Estos pesos son los que concuerdan con GNB (asumimos distribución gaussiana e independencia)
¿Qué tal si no queremos asumir GNB?
En el marco probabilístico buscamos maximizar la probabilidad asignadas a la clasificación, es decir el likehood condicional de los datos
Entre más grande la probabilidad asignada, el producto es más grande. Sin embargo, nos conviene trabajar con el $log$ likehood
Para una $Y$ binaria
Entre más grande la probabilidad asignada, el producto es más grande. Sin embargo, nos conviene trabajar con el $log$ likehood
Existen dos tipos de términos
Fijarse que $Y$ se usa para apagar y prender los términos dependiendo si es $0$ o $1$
Si
entonces
Remplazando
Que no tiene forma cerrada. Como queremos maximizar, usaremos Gradient Ascent
Actualización de pesos
Con regularización $l2$
- Cuando no se cumple GNB, entonces LR y GNB aprenden diferentes funciones, pero en datos infinitos ambos convergen.
Metodología general
Problemas
- Errores: sesgo + varianza + error
- Subajuste: modelo muy sencillo
- Sobreajuste: modelo muy complejo
No muy prometedor
- ¿Qué tan bueno es nuestro modelo/sistema?
Poder predictivo
Marco general
En el caso supervisado, quiere decir que tengo $n$ ejemplos (datos) $(X,y)$
Vamos a esconderle unos datos a nuestro modelo, y vemos como se desempeña con ellos
Comparo las predicciones $y'$ de estos datos, con las que debió haber dado $y$
Datos
Entrenamiento datos que uso para calcular parámetros del modelo
Prueba datos que uso para comparar predicciones del modelo con lo que debería dar
Pecado capital
Nunca uso datos de entrenamiento para cuantificar el desempeño de mi modelo
!Nunca!
De hecho...
No veo nada sobre mis datos de prueba, ni siquiera las salidas del sistema
!Nada!
Pero es muy informativo ver las salidas de las predicciones
Datos desarrollo
Desarrollo datos que uso para ganar intuición de qué está bien o mal con el modelo
Tipos de datos
- Entrenamiento
- Desarrollo
- Prueba
¿De dónde salen?
Algunos problemas que estudiamos ya tienen está división
train, dev y test
o train y test
Dilema
Más datos, mejor parámetros
Los datos supervisados son caros
¡Ni modos! la certeza del desempeño es más valiosa
Kaggle
Sitio de competencias, nos dan datos de entrenamiento; semanas después nos dan datos de prueba, los predecimos les entregamos nuestras predicciones y nos evaluan
Otros casos
Nosotros decidimos, la cantidad de datos es un factor
- Suficientes
- Pocos
Suficientes
Nosotros hacemos la partición
- Suficientes: 60%, 20%, 20%
- Muchos: 80%, 10%, 10%
- Demasiados: 90%, 5%, 5%
Pocos
- Validación cruzada: $k$-fold
- Validación cruzada: One-left-out
- Bootstraping: muestreo con remplazo
¿Qué hay de la evaluación?
| Positivo | Negativo | |
|---|---|---|
| Positivo' | Verdadero positivo (TP) | Falso positivo (FP) |
| Negativo' | Falso negativo (FN) | Verdadero negativo (TN) |
Accuracy
De los que dije, cuales dije bien
Precisión
Positive predictive value
De los que dije positivo, cuales realmente eran positivos
Covertura (recall)
True positive rate, sensicibilidad
Cuantos positivos dije de los que debi haber dicho
Especificidad
Cuantos negativos dije de los que debi haber dicho
FPR
False positive rate
Cuantos negativos no dije, de todos los que dije
F-score
Cuantos negativos dije de los que debi haber dicho
Curva ROC
Grafico FPR contra Recall para distintos umbrales de decisión de positivo
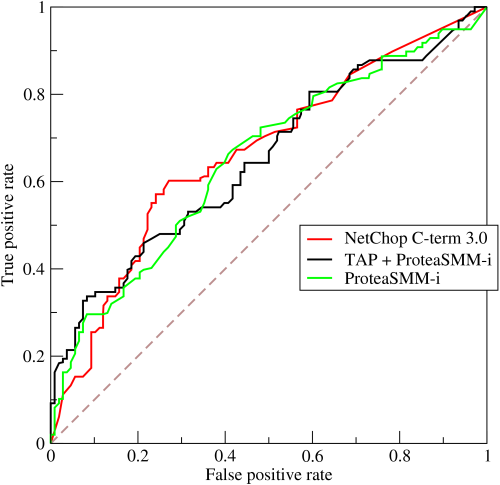
Curva ROC
Muestra el comportamiento cuando el umbral crece
Sistema ideal, al
Área bajo la curva (AUC)
Área bajo una curva ROC

Regresión lineal y, sub y sobre ajusto by Ivan V. Meza Ruiz is licensed under a Creative Commons Reconocimiento 4.0 Internacional License.
Creado a partir de la obra en http://turing.iimas.unam.mx/~ivanvladimir/slides/rpyaa/02_regresión.html.