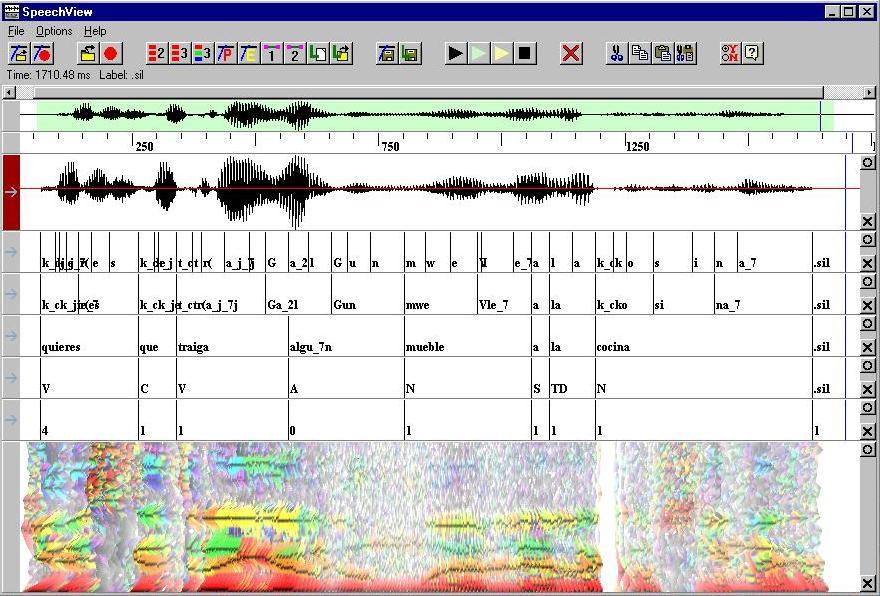
CSLU, SpeechViewer. Niveles de alófonos, sílabas fonéticas, palabras y break indices.
El Corpus DIME consiste en un conjunto de diálogos en el dominio del diseño de cocinas que fueron recopilados bajo el protocolo del experimento del Mago de Oz, en el que un ser humano familiarizado con la tarea pretende ser el sistema computacional y otro ser humano soluciona un problema, en este caso, diseñar una cocina, de manera cooperativa con el mago, y la interacción tanto lingüística como gráfica, se da a través de un sistema computacional. En nuestro experimiento el sujeto humano sabía que el Mago era también un ser humano. Los diálogos fueron grabados en un experimento controlado, y tanto el audio como el video de la interacción fueron recopilados automáticamente. Este tipo de tarea constituye un ejemplo de diálogo práctico, y el material recolectado ha sido objeto de análisis y etiquetado en varios niveles de representación lingüística, tales como el fonético, fonológico, prosódico y entonativo, léxico, sintáctico y pragmático, y esta información constituye la base empírica para la investigación del lenguaje conversacional en diálogos cooperativos. Actualmente se cuenta con varias metodologías y herramientas de transcripción para este corpus, y el recurso se emplea en varios experimentos de lingüística computacional en el contexto del proyecto, y constituye un recurso único para el estudio de este tipo de diálogos en español.
Niveles de etiquetado en el corpus DIME
Los etiquetados del Corpus DIME están organizados en niveles. El proceso se facilita y es más eficaz si los niveles se etiquetan siguiendo cierto orden. Los niveles y el orden sugerido para su etiquetado son: alófonos, sílabas fonéticas, palabras, índices de ruptura (Break Indices, del esquema ToBI), partes del habla (Parts of Speech, P.O.S.), reparaciones del habla (speech repairs), entonación (con el esquema INTSINT) y actos de diálogo (con el esquema DIME-DAMSL). Los etiquetados de INTSINT y de DIME-DAMSL en realidad pueden hacerse sin depender directamente de los otros. El etiquetado de actos de diálogo se apoya en dos etiquetados adicionales: inicio y fin de transacción, y cargos-abonos, que se describen brevemente más abajo.
Alófonos
En este nivel se etiquetan los alófonos realizados por el hablante. Se etiqueta lo que realmente dijo, aunque lo haya dicho infringiendo las reglas ortográficas. El etiquetado de alófonos se hace usando el alfabeto fonético Mexbet, en particular el conjunto de símbolos denominado T54 el cual también se usa para etiquetar el nivel de alófonos en el Corpus DIMEx100. El software que usamos para hacer este etiquetado es SpeechViewer, de CSLU Toolkit; en forma preliminar, puede usarse TranscribeMex para producir etiquetados automáticas sin alineación de tiempo que posteriormente se alinean manualmente con SpeechViewer. Para etiquetar alófonos, se puede usar el manual disponible en esta liga.
Sílabas fonéticas
Una sílaba fonética es un agrupamiento de segmentos (alófonos), que se realizan en una misma emisión de voz, que puede coincidir o no con la sílaba canónica del enunciado. Al ser el enunciado (elocución) un evento fonético, puede presentarse el fenómeno de resilabificación; es decir, la modificación de las sílabas canónicas por parte de un hablante en un contexto determinado. La resilabificación ocurre típicamente al inicio y al final de palabra. Existen ciertos casos, donde frecuentemente los hablantes tienden a modificar la estructura silábica canónica:
Este nivel de etiquetado se hace con SpeechViewer, y puede apoyarse con TranscribeMex para generar la separación silábica canónica, que después se somete a verificación auditiva para identificar casos de resilabificación.
Palabras
El nivel de palabras es una transcripción ortográfica; es decir, se escriben con ortografía correcta las palabras que el hablante “quiso decir”, aunque quizá haya dicho mal (incompletas, alterando fonemas, etc.). Se etiqueta usando las letras minúsculas del alfabeto inglés, adicionando el acento ortográfico y la letra eñe del idioma español. El acento ortográfico se representa con el símbolo _7, y la eñe con el símbolo n~, ambos tomados del alfabeto Mexbet. Para etiquetar palabras, se puede usar el manual disponible en esta liga.
Partes del habla (Part of Speech tagging)
En el nivel de Partes del Habla (Parts of Speech, P.O.S.) etiquetamos la categoría sintáctica a la cual pertenece cada una de las palabras en la transcripción ortográfica de un enunciado. Entre otras, se etiquetan: sustantivos, verbos, artículos, adjetivos, adverbios, etc. Para ello, se definió un conjunto de etiquetas, basado en diversas referencias y adaptado para las necesidades del Proyecto DIME. El manual para etiquetado de P.O.S. está disponible en esta liga.
Break indices
El nivel de Break Indices (índices de ruptura) está basado en el esquema ToBI (Tone and Break Indices, de Beckman, M.E., Diaz-Campos, M., Tevis McGory, J., Morgan, T.A. Intonation across Spanish, in the Tones and Break Indices framework. 1999), y ha sido modificado para las necesidades propias del Proyecto DIME. Representa los diversos grados de ruptura (o de unión) entonativa entre palabras de un enunciado. Se percibe como silencios o pausas de diversa duración entre las palabras. En este nivel se usa un conjunto de etiquetas dadas como números del 0 (cero) al 4, donde a menor valor del índice se tiene una menor ruptura y, a mayor valor, una mayor ruptura. El 0 representa unión por reducción vocálica o sinalefa; el 4 representa frontera entonativa, es decir, inicio o fin de enunciado. Los índices intermedios representan: 1, separación normal entre palabras (sin ningún tipo de unión); 2, reparación del habla; 3, enumeración. Para etiquetar Break Indices, consultar el manual correspondiente, disponible en esta liga.
Entonación
El etiquetado en el nivel de entonación representa el contorno de la frecuencia fundamental (f0) de la señal del habla. Este etiquetado se produce mediante un proceso semi-automático que genera etiquetas con el modelo denominado INTSINT (International Transcription System for Intonation), de Daniel Hirst. Este modelo de etiquetado se apoya en el algoritmo MOMEL (Modelisation de Melodie), implementado en la herramienta de software denominada M.E.S. (Motif Environment for Speech). A grandes rasgos, el proceso inicia con la preparación del archivo de audio, originalmente en formato WAV, para transformarlo mediante la herramienta M.E.S al formato de ésta última (denominado segment); después, automáticamente se extrae del archivo una representación de la f0, que luego se usa para crear una curva estilizada del contorno de f0, usando el algoritmo MOMEL. La curva estilizada se verifica perceptivamente por el etiquetador humano, mediante la vista y el oído, y en caso necesario, se ajusta manualmente para hacerla igual a la f0 originalmente extraida. Una vez cumplida la verificación perceptiva, se producen automáticamente las etiquetas de entonación INTSINT. Para este etiquetado está disponible un manual de verificación perceptiva de curvas de entonación usando el software Phonedit (descendiente de M.E.S.) y además se puede consultar el tutorial de M.E.S., disponible en:
http://www.lpl.univ-aix.fr/ext/projects/mes_signaix.htm/mes_signaix.tutorial.html
Ejemplos de los niveles de etiquetado del Corpus DIME:
CSLU, SpeechViewer. Niveles de alófonos,
sílabas fonéticas, palabras y break indices.
Se ofrecen los siguientes archivos:
Ejemplo 1: Una elocución etiquetada en los niveles: alófonos, sílabas fonéticas, palabras y break índices (sin reparaciones de habla)
| Texto: | ¿Quieres que traiga algún mueble a la cocina? |
| Audio: |  |
| Alófonos: |  |
| Sílabas fonéticas: | |
| Palabras: | |
| Break indices: | |
Ejemplo 2: Una elocución etiquetada con reparaciones de habla.
| Texto: | Y ahora un... la estufa un poco hacia el fregadero |
| Audio: | |
| Alófonos: | |
| Sílabas fonéticas: | |
| Palabras: | |
| Break indices: | |
| REPARACIONES DEL HABLA: | |
| Marcador del discurso: | |
| Tipo de reparación: | |
| Estructura de reparación: | |
| Palabras de reparación: | |
| Part of Speech: | |
Ejemplo 3: Una transacción etiquetada con cargos y abonos, DIME-DAMSL y modalidad.
| Video: | |
| Etiquetado cargos y abonos: | |
| Etiquetado DIME-DAMSL: | |
| Modalidad: | |
Los ejemplos 1 y 2, los puedes ver a través del software CSLU toolkit como se muestra en la figura anterior.
NOTA. Para bajar los archivos dar click con el boton derecho del mouse sobre el icono de la flecha y escoger la opción "guardar destino como"