Lógica Computacional
Nota 12. Resolución SLD y programación lógica11Esta nota se base en material elaborado por el prof. Favio Miranda y en el libro de Ben-Ari M., Mathematical Logic for Computer Science
La resolución fue originalmente desarrollada como un método para la demostración automática de teoremas. Una forma restringida de resolución se usa para obtener cómputos. Un programa se expresa como un conjunto de cláusulas y una consulta o meta es una cláusula que colisiona con las cláusulas de programa. La meta se asume como la negación del resultado del programa. Si la refutación es exitosa, la meta no es consecuencia lógica del programa, pero su negación sí lo es. Las unificaciones que toman lugar durante la refutación constituyen la respuesta buscada.
1 Refutación de una cláusula meta
La teoría de lenguajes formales nos provee de un símbolo de función binario para la concatenación, denotado por el operador infijo , y tres predicados:
-
, es una subcadena de .
-
, es un prefijo de .
-
, es un sufijo de .
Los axiomas de la teoría son:
En forma clausular tenemos (las cláusulas de programa):
Podemos demostrar que la fórmula es consecuencia lógica al refutar su negación , como sigue:
En lugar de determinar si una cláusula meta cerrada es consecuencia lógica de los axiomas, podemos averiguar si lo es. Vamos a intentar refutar la negación de la fórmula: . Una literal universalmente cuantificada es una cláusula, así que procedemos a la refutación:
No solo demostramos que es consecuencia lógica de los axiomas, también hemos realizado un cómputo para determinar el valor para que satisface .
2 Cláusulas de Horn y resolución SLD
2.1 Cláusulas de Horn
Definición 2.1.
Una cláusula de Horn es una cláusula de la forma
con a lo más una literal positiva. La literal es la cabeza y las literales negadas son el cuerpo.
-
Un hecho es una cláusula de Horn unitaria positiva .
-
Una cláusula meta es una cláusula de Horn sin literal positiva .
-
Una cláusula de programa es una cláusula de Horn con una literal positiva y una o más literales negativas.
En programación lógica se prefiere el uso de , el operador de implicación inverso, sobre el operador de implicación hacia adelante . En lugar de podemos optar también por la notación de Prolog, :-.
Definición 2.2.
Los siguientes conceptos serán de utilidad:
-
Un conjunto de cláusulas de Horn que no sean cláusulas meta y cuyas cabezas tengan el mismo símbolo de predicado es un procedimiento.
-
Un conjunto de procedimientos es un programa lógico.
-
Un procedimiento compuesto por hechos sin variables es una base de datos.
Ejemplo 2.3.
El siguiente programa tiene dos procedimientos y ; es también una base de datos.
-
1.
.
-
2.
.
-
3.
.
-
4.
.
-
5.
.
-
6.
.
-
7.
.
-
8.
.
-
9.
.
-
10.
.
2.2 Sustitución de respuesta correcta
Definición 2.4.
Sea un programa y una cláusula meta. Una sustitución para las variables en es una sustitución de respuesta correcta si , donde la cuantificación universal se toma sobre todas las variables libres en .
Observe que la cláusula meta tiene implícitamente la forma negada, que es adecuada para efectuar la refutación por resolución. Así, equivale a una conjunción de literales positivas que se satisface siempre que el programa lógico se satisfaga. Es decir, dado un programa , una cláusula meta , y una sustitución de respuesta correcta , por definición , así:
Por lo tanto, para cualquier sustitución que convierta a la conjunción anterior en una fórmula sin variables, es verdadera en todo modelo de . De allí la terminología pues la sustitución da una respuesta a la consulta expresada por la cláusula meta.
Ejemplo 2.5.
Sea el conjunto de todos los axiomas de la aritmética.
-
Sea la cláusula meta y la sustitución :
Como , es una sustitución de respuesta correcta para .
-
Sea la cláusula meta y la sustitución :
Como , es una sustitución de respuesta correcta para .
-
Sea la cláusula meta y , la sustitución vacía:
Como , no es una sustitución de respuesta correcta para .
2.3 Resolución SLD
Definición 2.6.
(Resolución SLD) Sea un programa lógico y una cláusula meta. Una derivación por resolución SLD es una secuencia de pasos de resolución entre las cláusulas meta y las cláusulas de programa. La primer cláusula meta es . se deriva de seleccionando una literal , eligiendo un cláusula tal que la cabeza de unifica con mediante un umg y realizando:
-
Observe como el lado derecho de reemplaza a la literal .
-
Una refutación SLD es una derivación SLD de .
-
La regla para seleccionar una literal de una cláusula meta es la regla de cómputo.
-
La regla para escoger una cláusula es la regla de búsqueda.
Ejemplo 2.7.
Sea una cláusula meta para el programa en el Ejemplo 2.3. En cada paso debemos escoger una literal dentro de dicha cláusula meta y también una cláusula de programa cuya cabeza colisione con la literal seleccionada.
Por lo tanto, tenemos una refutación para bajo la sustitución . Como la resolución es correcta, concluimos que:
de manera que es una sustitución de respuesta correcta, y es verdadera para cualquier modelo de .
Definición 2.8.
A continuación se dan algunas definiciones para saber de donde proviene el término SLD para el tipo de resolución que estamos estudiando:
- Resolución lineal.
-
Es una regla en la cual la resolución utiliza siempre la cláusula meta actual que se va generando.
- La regla de cómputo o función de selección.
-
Se refiere a la regla que indica cual átomo de la meta se elige para aplicar resolución. En Prolog se elige la literal más a la izquierda de la cláusula meta.
- Una cláusula definida
-
es de la forma con . Si , la cláusula es un hecho.
- Resolución SLD
-
(Selected, linear, definite resolution) Resolución lineal con función de selección tomando cláusulas definidas.
Notemos que la resolución SLD es muy sensible a las reglas de cómputo y de búsqueda que se emplean. Puede que para un programa y una cláusula meta existan varias derivaciones produciendo distintas sustituciones de respuesta correcta; o, dependiendo de estas reglas, puede que la derivación entre en un ciclo y no termine, o bien, puede terminar con una falla al no poder realizar más pasos de la derivación.
Ejemplo 2.9.
Considere de nueva cuenta el programa en el Ejemplo 2.3. En el Ejemplo 2.7 se demostró que hay una refutación para la meta con sustitución de respuesta correcta . Realice una refutación distinta para la misma meta obteniendo una sustitución de respuesta correcta diferente.
La refutación anterior produce la sustitución , por lo que puede haber más de una sustitución de respuesta correcta para una cláusula meta.
Ejemplo 2.10.
Suponga que la regla de cómputo toma la última literal en la cláusula meta, y que la regla de búsqueda escoge primero las cláusulas más abajo y luego las de arriba. Realice tres pasos de la refutación de la cláusula meta .
Ejemplo 2.11.
Si ahora suponemos que la regla de cómputo toma la primera literal en la cláusula meta, y la regla de búsqueda recorre las literales de abajo hacia arriba, podemos intentar la refutación de del siguiente modo:
Aunque existe una sustitución de respuesta correcta como se ha visto previamente, esta refutación en particular ha fallado, ya que no hay cláusula de programa que pueda unificarse con .
Como se verá más adelante, Prolog toma la literal más a la izquierda de la meta y recorre las cláusulas de programa de arriba hacia abajo, hasta encontrar un cláusula con la cual realizar resolución. Si la refutación actual falla, Prolog regresa a un punto de retorno para intentar una refutación distinta con la misma literal más a la izquierda de la meta.
2.4 Teoremas de correctud y completud
Teorema 2.12 (Correctud de las resolución SLD).
Sea un conjunto de cláusulas de programa, una regla de cómputo y una cláusula meta. Suponga que hay una refutación SLD de . Sea la composición de los unificadores usados en la refutación y sea la restricción de a las variables de . Entonces es una sustitución de respuesta correcta para .
Demostración. Por definición de , , así que , lo cual es insatisfacible porque la resolución es correcta. Pero que sea insatisfacible implica que . Como esto es cierto para cualquier sustitución en las variables libres de , se sigue que , es decir, es una sustitución de respuesta correcta para .
Teorema 2.13 (Completud de las resolución SLD).
Sea un conjunto de cláusulas de programa, una regla de cómputo, una cláusula meta y una sustitución de respuesta correcta. Luego, hay una refutación SLD de a partir de tal que es la restricción de la composición de los unificadores de a las variables de .
La refutación SLD es completa para cláusulas de Horn, pero no en general.
Ejemplo 2.14.
Consideremos el conjunto de cláusulas insatisfacibles:
no es un conjunto de cláusulas de Horn puesto que tiene dos literales positivas. Aunque tiene una refutación por resolución general, ya que es insatisfacible y la resolución es completa:
Esta no es una refutación SLD porque el paso final resuelve dos cláusulas meta, no una cláusula meta con una de las cláusulas del programa en .
Refutaciones como cómputos
Dado un programa y una consulta expresada como una cláusula meta, el resultado de una refutación exitosa es una respuesta obtenida de las sustituciones llevadas a cabo por la unificación. En lenguajes de programación, el control del cómputo se construye explícitamente por el programador, quien puede ocupar estructuras de control como:
if(...) ... else ...
for(...) ...
En programación lógica, el programador escribe fórmulas declarativas que describen la relación entre la entrada y la salida. El motor de inferencia de la resolución provee una estructura de control implícita uniforme, así que se mitiga la tarea del programador de especificar el control explícitamente. Los lenguajes de programación lógicos permiten abstraer la estructura de control. Dicho control depende fuertemente de las reglas de cómputo y de búsqueda.
2.5 Árbol SLD
El conjunto de derivaciones SLD para un programa lógico puede ser visto como un árbol.
Definición 2.15.
Sea un conjunto de cláusulas de programa, una regla de cómputo y una cláusula meta. Un árbol SLD se genera del siguiente modo: La raíz se etiqueta con la cláusula meta . Dado un nodo etiquetado con un cláusula meta , se produce un hijo por cada cláusula meta nueva que se obtiene al resolver la literal escogida por con la cabeza de una cláusula en .
Ejemplo 2.16.
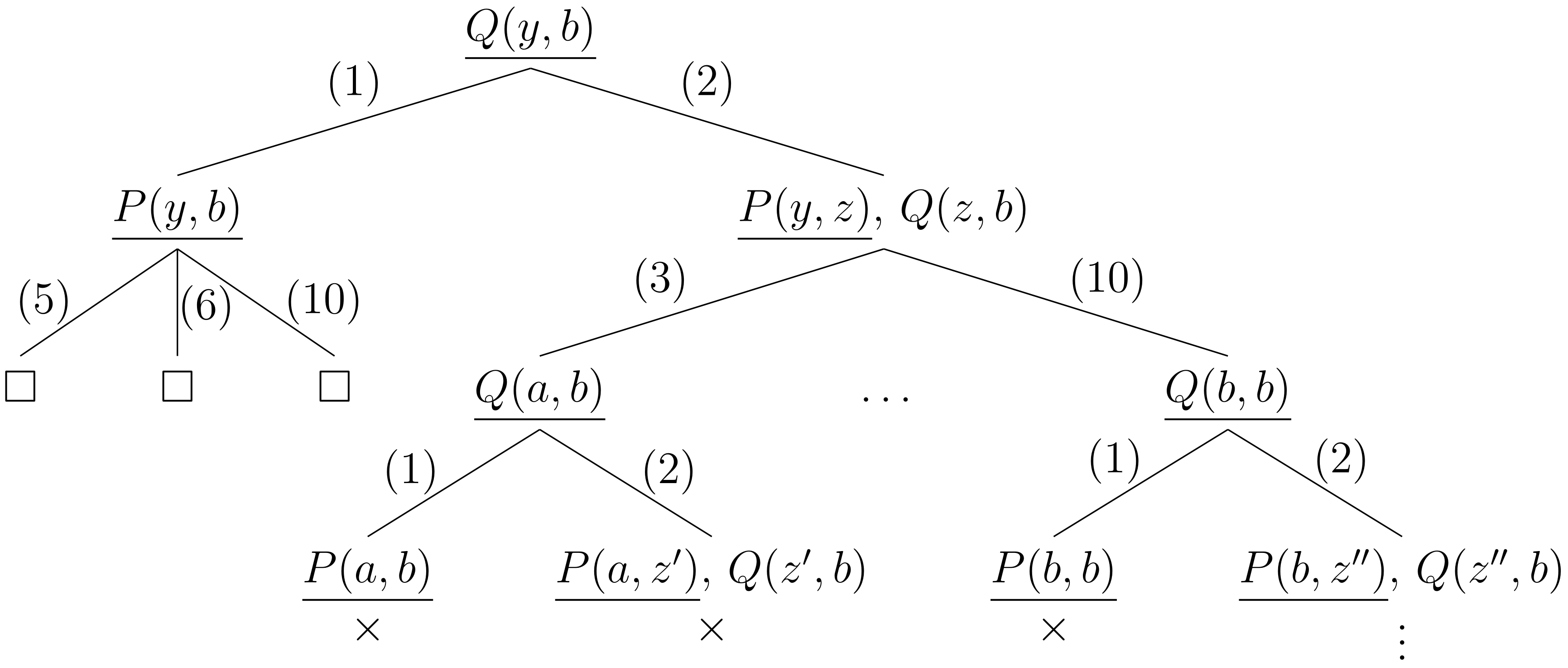
La Fig. 1 muestra un árbol SLD para la cláusulas de programa en el Ejercicio 2.3 y la cláusula meta . La regla de cómputo escoge siempre la literal más a la izquierda en la cláusula meta, la cual está subrayada. El número en la arista se refiere al número de la cláusula de programa que colisionó con la cláusula meta.
Definición 2.17.
En un árbol SLD, una rama que conduce a una refutación es una rama de éxito. Una que lleva a una cláusula meta cuya literal seleccionada no unifica con ninguna cláusula de programa es una rama de fallo. Una rama que corresponda a una derivación que no termina es una rama infinita.
Puede ser que haya muchos árboles SLD, uno para cada regla de cómputo; sin embargo, el siguiente teorema nos dice que todos los árboles que se obtienen son similares.
Teorema 2.18.
Sea un programa y una cláusula meta. Entonces todos los árboles SLD para y tienen un número infinito de ramas de éxito o tienen todos el mismo número finito de ramas de éxito.
Definición 2.19.
Una regla de búsqueda es un procedimiento para buscar una refutación en un árbol SLD. Un procedimiento de refutación SLD es el algoritmo de resolución SLD junto con la especificación de una regla de cómputo y una regla de búsqueda.
La resolución SLD es completa independientemente de la regla de cómputo, pero solo afirma la existencia de una refutación. La regla de búsqueda determinará si se encuentra o no la refutación, y qué tan eficiente es el procedimiento. Una búsqueda por amplitud de un árbol SLD, donde se revisan los nodos a cada nivel antes de buscar más profundamente, garantiza encontrar una rama de éxito si es que la hay. En cambio, una búsqueda a profundidad puede elegir recorrer una rama que no termina. En la práctica, se prefiere la búsqueda a profundidad porque necesita mucha menos memoria: una pila del camino que se está explorando, donde cada elemento registra qué rama se tomó en cada nodo y las sustituciones que se realizaron en ese nodo. En una búsqueda por amplitud, esta información debe almacenarse para todas las hojas en el nivel actual de la búsqueda.
Definición 2.20.
Un árbol de prueba por refutación basado en resolución SLD es un árbol binario (aunque su forma es lineal) con nodos etiquetados con cláusulas meta o cláusulas de programa, construido mediante aplicaciones de la regla de resolución binaria del siguiente modo: si es una cláusula resolvente a partir de la cláusula de programa , la cláusula meta y la regla de cómputo , entonces el árbol tendrá a como hijo de y de . Este procedimiento se repite tomando ahora a como la nueva cláusula meta, y termina cuando .
La Fig. 2 muestra el árbol de prueba por refutación basado en resolución SLD obtenido a partir del Ejemplo 2.7.
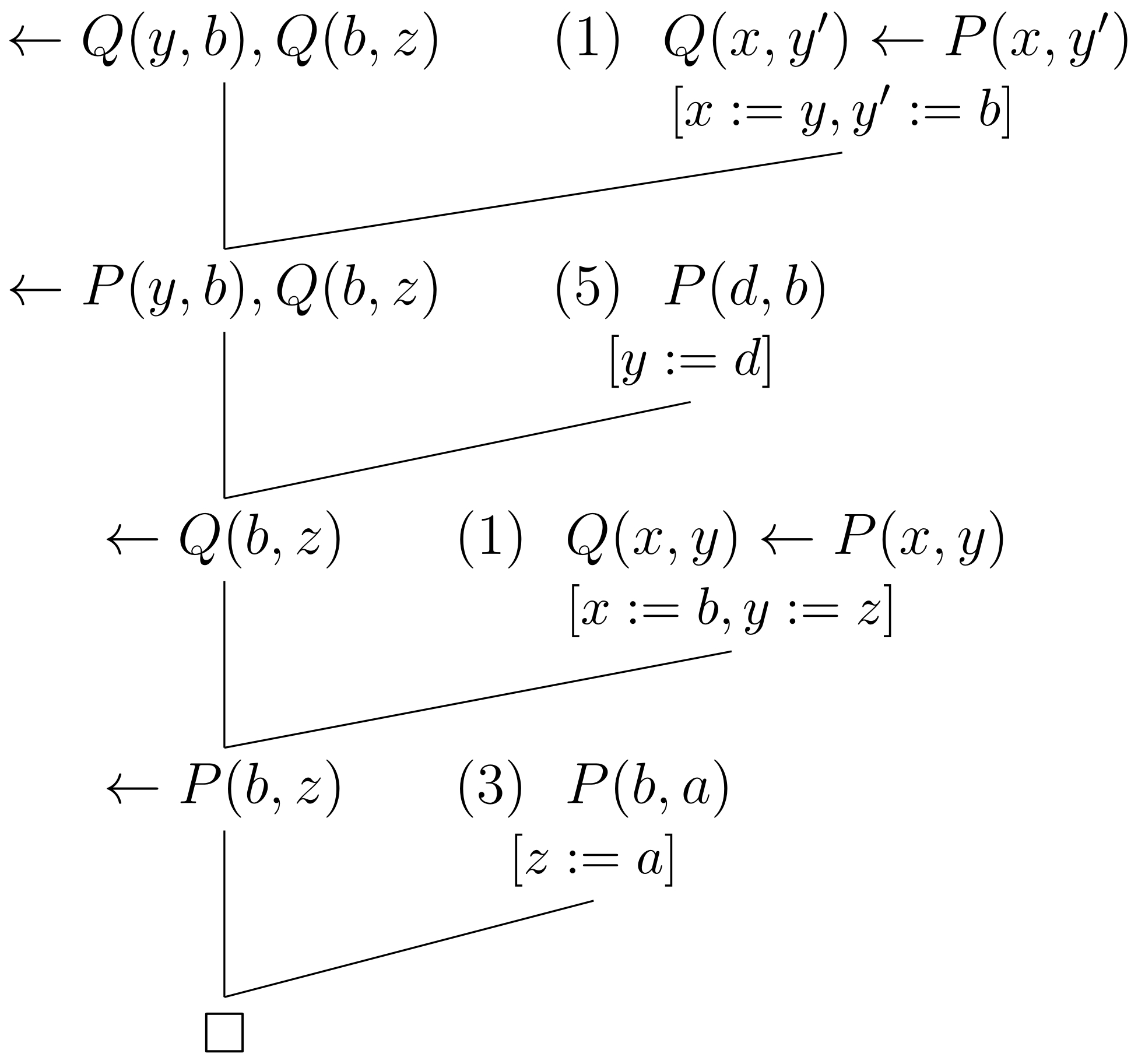
3 Prolog
Prolog fue el primer lenguaje de programación lógica. La regla de cómputo en Prolog escoge la literal más a la izquierda. La regla de búsqueda toma cláusulas de arriba hacia abajo. La notación en Prolog difiere de la notación matemática que hemos usado:
-
a)
las variables inician con letras mayúsculas,
-
b)
los predicados inician con letras minúsculas,
-
c)
todas las declaraciones terminan con un punto (
.), y -
d)
el símbolo
:-se usa en lugar de .
Ejemplo 3.1.
Reescribamos el programa del Ejemplo 2.3 usando la notación de Prolog .
ancestro(X,Y) :- progenitor(X,Y). ancestro(X,Y) :- progenitor(X,Z),ancestro(Z,Y). progenitor(bob, allen). progenitor(catherine, allen). progenitor(dave, bob). progenitor(ellen, bob). progenitor(fred, harry). progenitor(harry, george). progenitor(ida, george). progenitor(joe, bob).
Usamos progenitor cuando hablamos de la relación ser papá o mamá. El procedimiento para ancestro da un significado declarativo de este concepto en términos de la relación progenitor:
-
Xes unancestrodeYsiXes unprogenitordeY. -
Xes unancestrodeYsi hayZtal queXes unprogenitordeZ,Zes unancestrodeY.
3.1 Búsqueda a profundidad
La búsqueda en un árbol SLD generado por Prolog sigue una búsqueda a profundidad, lo que puede originar la no terminación de un cómputo, incluso si existe un cómputo que en efecto termina. Un programador de Prolog debe ordenar cuidadosamente las cláusulas dentro de un procedimiento y las literales dentro de las cláusulas para evitar que la ejecución no termine. Considere los siguientes dos programas en Prolog :
test :- p(X).
p(a).
p(X) :- p(f(X)).
test :- p(X).
p(X) :- p(f(X)).
p(a).
Al realizar la consulta ?-test. el programa de la izquierda terminará en el segundo paso de la resolución, mientras que el de la derecha efectuará la resolución con p(X) :- p(f(X)). en cada paso de la derivación y nunca terminará. De aquí la importancia de acomodar bien las cláusulas en el programa.
Como una falla puede ocurrir en cualquier paso, Prolog almacena una lista de puntos de retorno22Backtrack points.. Estos puntos representan nodos previos en el árbol SLD donde existen ramas adicionales por explorar.
Un concepto importante al programar en Prolog es el forzar la falla. Esto se implementa por el predicado fail. En esencia, una vez llegado el predicado fail se obliga a regresar al punto de retorno inmediato anterior. Prolog carece de estructuras iterativas tales como los ciclos for y while, así que la recursión y el forzar la falla son técnicas de programación fundamentales en este lenguaje. Por ejemplo, si al programa en Prolog del Ejemplo 3.1 le damos la cláusula meta ?- ancestro(Y,bob),ancestro(bob,Z),format("Y: ~w, Z: ~w\n", [Y,Z]),fail. se imprime en pantalla lo siguiente
Y: dave, Z: allen Y: ellen, Z: allen Y: fred, Z: allen false.
3.2 Prolog y la teoría de programación lógica
Predicados no lógicos
Los predicados no lógicos son predicados cuyo propósito principal es generar efectos secundarios. El ejemplo obvio son los predicados de entrada y salida (I/O), como read, write y print, que no tienen significado declarativo como fórmulas lógicas.
Aritmética
Prolog deja la programación lógica teórica en su tratamiento de tipos de datos numéricos. Aunque es posible formalizar la aritmética en lógica de primer orden, hay dos problemas con este formalismo. Primero, sería algo incómodo, por ejemplo, al ejecutar una consulta sobre el número de empleados en una tienda departamental y recibir como respuesta el término en lugar de 5. El segundo problema es la ineficiencia de la resolución como método de computación numérica.
Prolog soporta la aritmética estándar. La sintaxis es la de un predicado con un operador infijo, a saber, Result is Expression. La siguiente cláusula obtiene el precio de lista y el descuento de una base de datos, y calcula el valor del Precio después de aplicarle el descuento:
precio_de_venta(Articulo, Precio):- precio_de_lista(Articulo, Lista), porcentaje_descuento(Articulo, Descuento), Precio is Lista - Lista * Descuento / 100.
Los predicados aritméticos difieren de los predicados ordinarios porque son de ida únicamente, no como lo es la unificación. Si 10 is X+Y, X y Y podrían ser unificados con 0 y 10, y al tomar puntos de retorno, podrían ser unificados con 1 y 9, y así sucesivamente. Sin embargo, esto es ilegal. En Result is Expression, Expression debe ser evaluada a un valor numérico, entonces dicho valor es unificado con Result (quien es típicamente una variable que no se ha instanciado).
Los predicados aritméticos no son enunciados de asignación. El siguiente programa no es correcto:
precio_de_venta(Articulo, Precio):- precio_de_lista(Articulo, Lista), porcentaje_descuento(Articulo, Descuento), Precio is Lista - Lista * Descuento / 100, porcentaje_iva(Articulo, Impuesto), Precio is Precio * (1 + Impuesto / 100).
Una vez que Precio ha sido unificado cualquier intento de unificarlo una vez más fallará, justo como una variable en una fórmula lógica no puede ser modificada una vez que una sustitución por una constante tal como se ha aplicado. Una variable adicional debe ser usada para guardar el valor intermedio.
precio_de_venta(Articulo, Precio):- precio_de_lista(Articulo, Lista), porcentaje_descuento(Articulo, Descuento), Precio1 is Lista - Lista * Descuento / 100, porcentaje_iva(Articulo, Impuesto), Precio is Precio1 * (1 + Impuesto / 100).
Cut
La modificación más controversial a la programación lógica introducida en Prolog es el corte (cut). Considere el siguiente programa para calcular el factorial de un número :
factorial(0, 1). factorial(N, F):- N1 is N-1, factorial(N1, F1), F is N*F1.
Esta es una traducción a Prolog de la fórmula recursiva:
Ahora, supongamos que el resultado de este predicado es parte de otro procedimiento, tal vez uno que verifique una propiedad de números que son factoriales:
check(N) :- factorial(N, F), property(F).
Si check es invocado con N=0, llamará a factorial(0, F) lo que devolverá F=1 y llamará a property(1). Suponga que la llamada a este último predicado falla. Entonces el procedimiento de resolución SLD volverá a un punto de retorno, deshará la sustitución F=1, y lo intentará con la segunda cláusula en el procedimiento para factorial. La llamada recursiva a factorial(-1, F1) iniciará un cómputo que no terminará. Prolog imprimirá en pantalla ERROR: Out of local stack.
Digamos que property(X) verifica que X es un número par. Su declaración en Prolog es la siguiente:
property(X):- M is mod(X,2), M == 0.
Ponemos en el intérprete de Prolog el comando trace. que permite dar seguimiento a las llamadas de programa que se efectúan. Así, al tener la consulta [trace] ?- check(0). obtenemos en pantalla:
Call: (8) check(0) ? creep Call: (9) factorial(0, _3746) ? creep Exit: (9) factorial(0, 1) ? creep Call: (9) property(1) ? creep Call: (10) _3750 is 1 mod 2 ? creep Exit: (10) 1 is 1 mod 2 ? creep Call: (10) 1==0 ? creep Fail: (10) 1==0 ? creep Fail: (9) property(1) ? creep Redo: (9) factorial(0, _3746) ? creep Call: (10) _3750 is 0+ -1 ? creep Exit: (10) -1 is 0+ -1 ? Unknown option (h for help) Exit: (10) -1 is 0+ -1 ? Unknown option (h for help) Exit: (10) -1 is 0+ -1 ? Show context . . .
Se realizaran un número indefinido de llamadas a la segunda cláusula de factorial, y el stack se acabará sin terminar el cómputo.
Una llamada a factorial con argumento 0 tiene una única solución; si volvemos a puntos de retorno, la cláusula meta fallará. Esto puede ser evitado introduciendo un corte, denotado por un símbolo de exclamación, al final de la primer cláusula:
factorial(0, 1):- !.
El corte impide volver a puntos de retorno en este procedimiento. Una vez que el corte se ejecuta se tala una porción del árbol SLD e impide volver a puntos de retorno que no conviene explorar.
En el caso del factorial hay una mejor solución, a saber, agregar un predicado al cuerpo del procedimiento que explícitamente prevenga el comportamiento indeseado.
factorial(0, 1). factorial(N, F):- N > 0, N1 is N-1, factorial(N1, F1), F is N*F1.
Finalmente, considere el siguiente ejemplo de programación lógica en Prolog , donde el predicado take_even(X,Y) establece que en la lista Y figuran los elementos pares de X, por ejemplo, take_even([-5,-2,1,2,6,7],[-2,2,6]). Su definición es:
take_even([],[]). take_even([H|T],[H|T1]):- is_even(H), take_even(T,T1),!. take_even([_|T],T1):- take_even(T,T1). is_even(X):- M is mod(X,2), M == 0.
Hemos usado la variable anónima, denotada _ (guión bajo), en la definición de take_even([_|T],T1), ya que se está analizando el caso en el que la cabeza de la primer lista no es par, como dicho elemento no tiene importancia y no se hace referencia a él en ningún otro lado, se representa como una variable anónima.