De repesentaciones clásicas a representaciones avanzadas para NLP
Ivan Meza
Instituto de Investigaciones en Matemáticas Aplicadas y en Sistemas
Universidad Nacional Autónoma de México
Instrucciones código
$ git clone git@gitlab.com:ivanvladimir/nlp_notebooks.git
$ cd nlp_notebooks
$ pipenv install --ignore-pipfile
Es parte esencial de nuestra experiencia humana
Sin embargo, el lenguaje tiene propiedades escurridizas
Las palabras son muchas
Las palabras vienen en grupos
Hay "reglas"
- El gato camina por la barda
- La gato camina por la barda
- El gato camina barda la por
Hay estructura
- El gato camina por la barda
- Por la barda el gato camina
- Camina por la barda el gato
- Camina el gato por la barda
- Gato camina por el la barda
- Camina el gato barda por la
Las palabras tienen varios sentidos
La ambigüedad son las cosquillas del cerebro
- Hola, ¿cómo te llamas?
- Maria de los Ángeles ¿y tú?
- Daniel de Nueva York
El significado se compone
- El gato
- El gato camina
- El gato camina por la barda
- El gato camina por la barda una noche lluviosa que había mucho frío y donde nadie había pensado llevar un paraguas ante las evidentes señas de tormenta que presentaba el cielo cerrado y oscuro

| Propiedad | Valoración |
|---|---|
| Número de palabras | ✔ |
| Tipos de palabras | ✔ |
| "reglas" | ✔ |
| Estructuras | ✔ |
| Ambiguedad | ✔ |
| Composicionalidad | ✔ |
| Escalar | ✖ |
Entra a escena
Machine learning
Ir a código, ejecutar sólo PRIMERA PARTE
$ jupiter notebook
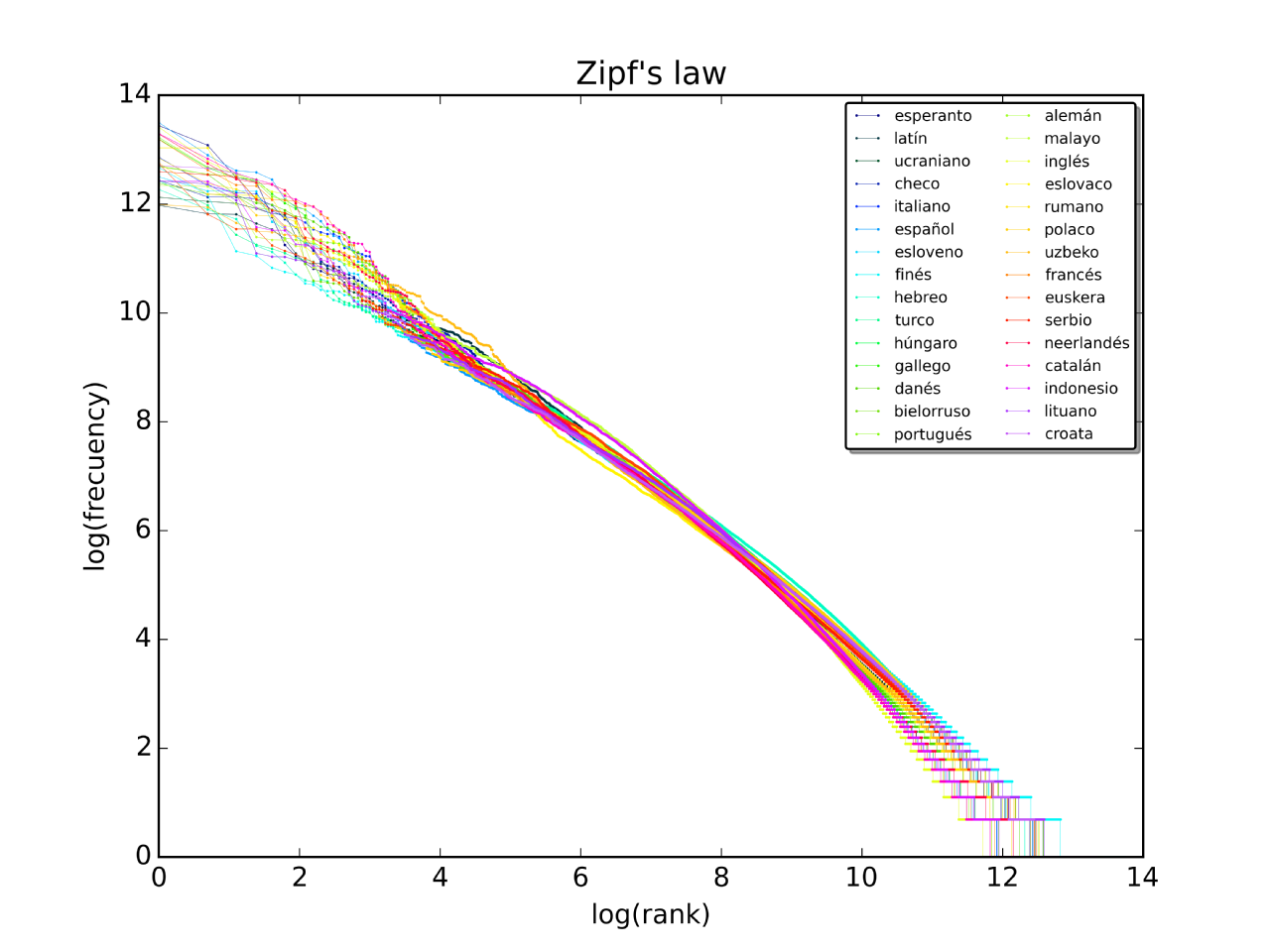
Zipf law
Pocas palabras que aparecen mucho, muchas palabras que aparecen poco
Ir a código, ejecutar sólo SEGUNDA PARTE
$ jupiter notebook
Ir a código, ejecutar sólo TERECERA PARTE
$ jupiter notebook
| Propiedad | Valoración |
|---|---|
| Número de palabras | ✔ |
| Tipos de palabras | ✖ |
| "reglas" | ✔ |
| Estructuras | ✖ |
| Ambiguedad | ~ |
| Composicionalidad | ✔ |
| Escalar | ✔ |
Ir a nuevo código
$ jupiter notebook
| Propiedad | Valoración |
|---|---|
| Número de palabras | ✔ |
| Tipos de palabras | ✖ |
| "reglas" | ✔ |
| Estructuras | ✖ |
| Ambiguedad | ✖ |
| Composicionalidad | ✔ |
| Escalar | ✔ |
Ninja de AA = Ninja en álgebra lineal
En aprendizaje automático es necesario manipular los datos matemáticamente (y pro-gramáticamente), necesitamos de herramientas matemáticas para alcanzar esto.
Vectores
Matrices
Matrices (cont.)
Vectores (cont.)
En realidad un vector es un tipo especial de matrix $\mathbb{R}^{n\times 1}$, para un vector columna
Vectores (cont.)
En realidad un vector es un tipo especial de matrix $\mathbb{R}^{1\times m}$, para un vector renglón
Transpuesta
La operación transpuesta nos permite cambiar entre vector columna y vector renglón
Transpuesta (cont.)
Operaciones con vectores
Operaciones con matrices
Otras: inversa $(XX^1=U)$, Trace $(x_{ii})$
Ir a nuevo código
$ jupiter notebook
| Propiedad | Valoración |
|---|---|
| Número de palabras | ?? |
| Tipos de palabras | ?? |
| "reglas" | ?? |
| Estructuras | ?? |
| Ambiguedad | ?? |
| Composicionalidad | ?? |
| Escalar | ?? |
MF: Sistemas de recomendación
Recomendar sin preguntar
- Filtros colaborativos: la conciencia de las masas
- Descubre la relación entre: objeto-sujeto
- Usado para casos desconocido
- Uso de aplicación: Amazon y netflix
| $D_1$ | $D_2$ | $\ldots$ | $D_m$ | |
| $U_1$ | $5$ | NA | $\ldots$ | $D_m$ |
| $U_2$ | $4$ | 3 | $\cdots$ | $5$ |
| $\vdots$ | $\vdots$ | $\vdots$ | $\ddots$ | $\vdots$ |
| $U_n$ | $NA$ | $NA$ | $\ldots$ | $5$ |
Variable latente
Variable auxiliar que gobierna el comportamiento de otras
Aumento dimensional
Concepto básico
$$ X \approx WH $$
$$ (n\times m) = (n\times k) ( k \times m) $$
W
$$\left[ \begin{array} a w_{11} & w_{12} & \cdots & w_{1k} \\ w_{21} & w_{22} & \cdots & w_{2k} \\ \vdots & \vdots & \ddots & \vdots \\ w_{n1} & w_{n2} & \cdots & w_{nk} \\ \end{array} \right] $$
Como piensa cada usuario en $k$ valores
H
$$\left[ \begin{array} a h_{11} & h_{12} & \cdots & h_{1m} \\ h_{21} & h_{22} & \cdots & h_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ h_{k1} & h_{k2} & \cdots & h_{km} \\ \end{array} \right] $$
Como piensan de cada documentos en $k$ valores
Métodos para calcular W y H
Gradient descent
Error
$$X[u,d]=x_{ud}$$ $$WH[u,d]=\sum_{i=1}^kw_{uk} h_{kd}=\hat{x}_{ud}$$
Gradiente
$$\hat{w}_{uk}=w_{uk}-\alpha \frac{dE_{ud}}{d_{uk}} $$$$\hat{h}_{kd}=h_{kd}-\alpha \frac{dE_{ud}}{d_{kd}} $$
Error cuadrático
$$(x_{ud}-WH[u,d])^2= (x_{ud}-\hat{x}_{ud})^2 = (x_{ud}-\sum_{i=1}^kw_{uk} h_{kj})^2$$Su derivada
$$\frac{dE_{ud}}{dw_{uk}}=-2(x_{ud}-\hat{x}_{ud})h_{uk} $$ $$\frac{dE_{ud}}{dh_{kd}}=-2(x_{ud}-\hat{x}_{ud})w_{kd} $$Finalmente
$$\hat{w}_{uk}=w_{uk}+2\alpha E_{ud} h_{kd}$$ $$\hat{h}_{kd}=h_{kd}+2\alpha E_{ud} w_{uk}$$Pero...
No tenemos todos los datos
Sólo se calcula para los observables
Regularización
Es gradient descent, podemos agregar regularización
$$\hat{w}_{uk}=w_{uk}+\alpha (2E_{ud} h_{kd}-\beta w_{uk})$$ $$\hat{h}_{kd}=h_{kd}+\alpha (2E_{ud} w_{uk}-\beta h_{kd})$$
Cambio de perspectiva: 1
Regresando
$$ X \approx WH $$
$X$ usuarios y su relación con los documentos ($n \times m$)
$W$ como piensan los usuarios ($n \times k$)
$H$ como pensamos sobre los documentos ($k \times m$)
Regresando
$$ X \approx WH $$
$X$ palabras y su relación con los documentos ($n \times m$)
$W$ como las palabras se relacionan con los temas ($n \times k$)
$H$ como los temas se relacionan con los documentos ($k \times m$)
$H$ es el diccionario (embeddings)
| Propiedad | Valoración |
|---|---|
| Número de palabras | ?? |
| Tipos de palabras | ?? |
| "reglas" | ?? |
| Estructuras | ?? |
| Ambiguedad | ?? |
| Composicionalidad | ?? |
| Escalar | ?? |
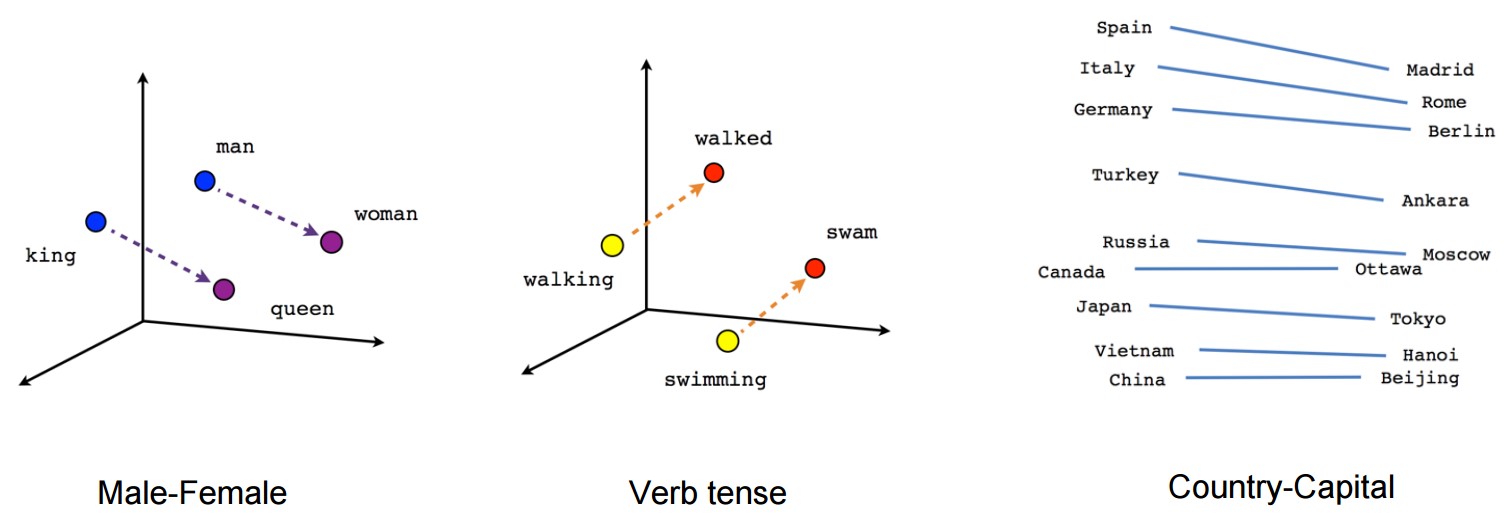
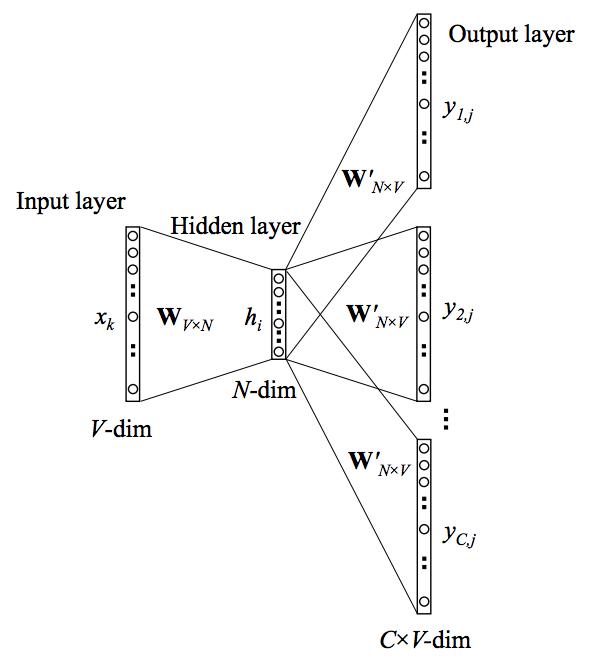
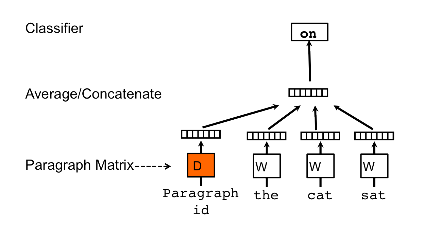
Word2vec

Ir a nuevo código
$ jupiter notebook


De repesentaciones clásicas a representaciones avanzadas para NLP by Ivan V. Meza Ruiz is licensed under a Creative Commons Reconocimiento 4.0 Internacional License.
Creado a partir de la obra en http://turing.iimas.unam.mx/~ivanvladimir/slides/nlp/presenentations_taller_nlp_uam.html.