Factorización de matrices
Sistemas de recomendación
Recomendar sin preguntar
- Filtros colaborativos: la conciencia de las masas
- Descubre la relación entre: objeto-sujeto
- Usado para casos desconociso
- Uso de aplicación: Amazon y netflix
| $D_1$ | $D_2$ | $\ldots$ | $D_m$ | |
| $U_1$ | $5$ | NA | $\ldots$ | $D_m$ |
| $U_2$ | $4$ | 3 | $\cdots$ | $5$ |
| $\vdots$ | $\vdots$ | $\vdots$ | $\ddots$ | $\vdots$ |
| $U_n$ | $NA$ | $NA$ | $\ldots$ | $5$ |
Variable latente
Variable auxiliar que gobierna el comportamiento de otras
Aumento dimensional
Concepto básico
$$ X \approx WH $$
$$ (n\times m) = (n\times k) ( k \times m) $$
W
$$\left[ \begin{array} a w_{11} & w_{12} & \cdots & w_{1k} \\ w_{21} & w_{22} & \cdots & w_{2k} \\ \vdots & \vdots & \ddots & \vdots \\ w_{n1} & w_{n2} & \cdots & w_{nk} \\ \end{array} \right] $$
Como piensa cada usuario en $k$ valores
H
$$\left[ \begin{array} a h_{11} & h_{12} & \cdots & h_{1m} \\ h_{21} & h_{22} & \cdots & h_{2m} \\ \vdots & \vdots & \ddots & \vdots \\ h_{k1} & h_{k2} & \cdots & h_{km} \\ \end{array} \right] $$
Como piensan de cada documentos en $k$ valores
Las predicciones (NA)
$$ WH[u,d] $$Métodos para calcular W y H
Gradient descent
Error
$$X[u,d]=x_{ud}$$ $$WH[u,d]=\sum_{i=1}^kw_{uk} h_{kd}=\hat{x}_{ud}$$
Gradiente
$$\hat{w}_{uk}=w_{uk}-\alpha \frac{dE_{ud}}{d_{uk}} $$$$\hat{h}_{kd}=h_{kd}-\alpha \frac{dE_{ud}}{d_{kd}} $$
Error cuadrático
$$(x_{ud}-WH[u,d])^2= (x_{ud}-\hat{x}_{ud})^2 = (x_{ud}-\sum_{i=1}^kw_{uk} h_{kj})^2$$Su derivada
$$\frac{dE_{ud}}{dw_{uk}}=-2(x_{ud}-\hat{x}_{ud})h_{uk} $$ $$\frac{dE_{ud}}{dh_{kd}}=-2(x_{ud}-\hat{x}_{ud})w_{kd} $$Finalmente
$$\hat{w}_{uk}=w_{uk}+2\alpha E_{ud} h_{kd}$$ $$\hat{h}_{kd}=h_{kd}+2\alpha E_{ud} w_{uk}$$Pero...
No tenemos todos los datos
Sólo se calcula para los observables
Regularización
Es gradient descent, podemos agregar regularización
$$\hat{w}_{uk}=w_{uk}+\alpha (2E_{ud} h_{kd}-\beta w_{uk})$$ $$\hat{h}_{kd}=h_{kd}+\alpha (2E_{ud} w_{uk}-\beta h_{kd})$$
Reducción dimensional
Solo fijarse en $H$
Regularización
Es gradient descent, podemos agregar regularización
$$\hat{w}_{uk}=w_{uk}+\alpha (2E_{ud} h_{kd}-\beta w_{uk})$$ $$\hat{h}_{kd}=h_{kd}+\alpha (2E_{ud} w_{uk}-\beta h_{kd})$$
Cambio de perspectiva: 1
Regresando
$$ X \approx WH $$
$X$ usuarios y surelación con los documentos ($n \times m$)
$W$ como piensan los usuarios ($n \times k$)
$H$ como pensamos sobre los usuarios ($n \times k$)
Cambio de representación
En recomendación tenemos: Usuarios y su relación con documentos
En modelado de tópicos: documentos y sus elementos
Elementos del documento
Muy directo en texto, palabras
Imágenes, segmentos de imágenes
| $w_1$ | $w_2$ | $\ldots$ | $w_m$ | |
| $D_1$ | $2$ | $3$ | $\ldots$ | $0$ |
| $D_2$ | $1$ | $2$ | $\cdots$ | $5$ |
| $\vdots$ | $\vdots$ | $\vdots$ | $\ddots$ | $\vdots$ |
| $D_n$ | $0$ | $0$ | $\ldots$ | $2$ |
Regresando
$k$ puede ser pensado como los témas de la colección
$$ X \approx WH $$
$X$ relación documentos y palabras ($n \times m$)
$W$ documentos en relación de $k$ temas ($n \times k$), de qué temás hablan los documentos
$X$ relación de los temas con las palabras ($k \times m$), que palabras usamos para hablar de los temas
A la lista de palabras de la temática se le llama tópico
Las palabras con más peso en $H$ representan las que tienen más influencia en el tema
| Tópico | Palabras |
| 0 | just people don think like know time ... |
| 1 | windows use dos using window ... |
| 2 | god jesus bible faith christian christ ... |
| 3 | thanks know does mail advance hi info ... |
| 4 | car cars tires miles 00 new engine ... |
| 5 | edu soon com send university internet ... |
| 6 | file problem files format win sound ftp ... |
| 7 | game team games year win play season ... |
| 8 | drive drives hard disk floppy software ... |
| 9 | key chip clipper keys encryption government ... |
Cambio de perspectiva: 2
Latent Dirichlet Allocation (LDA)
Técnico para el modelado de tópicos
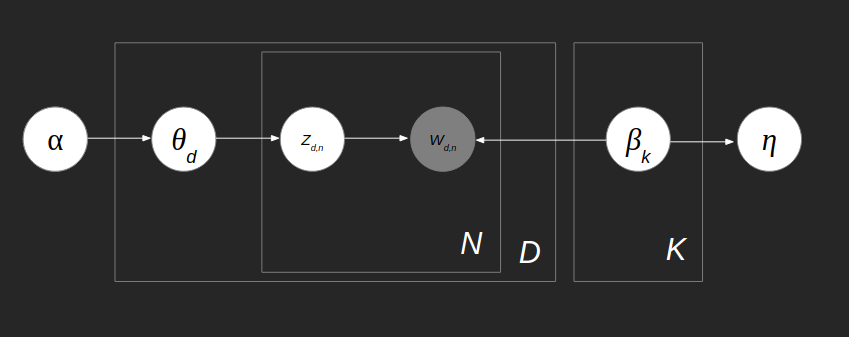
Intuición
- Para escribir una colección de documentos
- Preguntar a la inspiración $\alpha$ de que hablar, nos entrega una distribución de tópicos ($\theta_d$)
- Por cada topico ($k$) preguntar a la inspiración $\nu$ como hablar de ese tópico, nos entrega una distribución del vocabulario por tópico ($\beta_k$)
- Por cada palabra del documento
- Preguntar a ($\theta_d$) de qué tópic toca hablar $Z_{d,n}$
- Se decide la palabra $w$, dado el topico para esa palabra $Z_{d,n}$ y la distribución de palabras dado ese tópico $\beta_k$
- Para cada documento ($d$)
Resumen
- $\alpha$ la inspiración de qué topicos hablar
- $\nu$ la inspiración de cómo hablar sobre los tópicos
- $\theta_d$ son las probabilidades de los tópicos para el documento $d$
- $\beta_k$ son las probabilidades de las palabras para el tópico $k$
- $Z_{d,n}$ el tópico para la posición $n$, y documento $d$
- $w_{d,n}$ es la palabra para la posición $n$, y documento $d$
El modelo
$$ P(\alpha,\theta,Z,w,\nu,\beta) = \prod_{i=k}^K p(\beta_i|\nu)\\ ( \prod_{d=1}^D p(\theta_d|\alpha)\prod_{n=1}^N P(w_{d,n}|Z_{d,n},\beta_{Z_{d,n}}) P(Z_{d,n}|\theta_d) ) $$Lo que queremos aprender
$$ p(\beta,\theta,z|w,\nu,\alpha) $$Teneos ejemplos de documentos, es decir de $w$ en el modelo propuesto
$\nu$ y $\alpha$ escogemos algo fácil que genere distribuciones: Dirichlet
Lo que queremos aprender
$$ p(\beta,\theta,z|w,\nu,\alpha) $$Teneos ejemplos de documentos, es decir de $w$ en el modelo propuesto
$\nu$ y $\alpha$ escogemos algo fácil que genere distribuciones: Dirichlet
Dirichlet

Pocos picos altos, muchos picos bajos
$\beta$ y $\theta$ fácil cuando se sabe $Z_{d,n}$
$Z_{d,n}$ es muy dificil, el espacio es muy grande (variable latente), usamos aproximación: Gibbs sampling, variational methods
$\beta_k$
| Tópico | Palabras |
| 0 | edu com mail send graphics ftp pub available ... |
| 1 | don like just know think ve way use right ... |
| 2 | christian think atheism faith pittsburgh ... |
| 3 | drive disk windows thanks use card drives ... |
| 4 | hiv health aids disease april medical care ... |
| 5 | god people does just good don jesus sa ... |
| 6 | 55 10 11 18 15 team game 19 period play 23 ... |
| 7 | car year just cars new engine like bike ... |
| 8 | people said did just didn know time like wen ... |
| 9 | key space law government public use encryption ... |

Clustering, reducción dimensional y visualización by Ivan V. Meza Ruiz is licensed under a Creative Commons Reconocimiento 4.0 Internacional License.
Creado a partir de la obra en http://turing.iimas.unam.mx/~ivanvladimir/slides/rpyaa/07_cluster.html.