Long Short-Term Memory
Hasta ahora
- Fully connected: Todo a la vez
- CNN: relaciones de localidad
Secuencialidad
Problemas
- Texto
- Procesos
Ejemplos
- Clasificar texto:
el servicio de infinitum es tán bueno [irónico/no irónico] - Etiquetar
esta/pron es/vb una/det prueba/noun - Traducir esta es una prueba/this is a test
- Chatbots quiero un buelo a NY/qué día quieres salir
Recurrentes
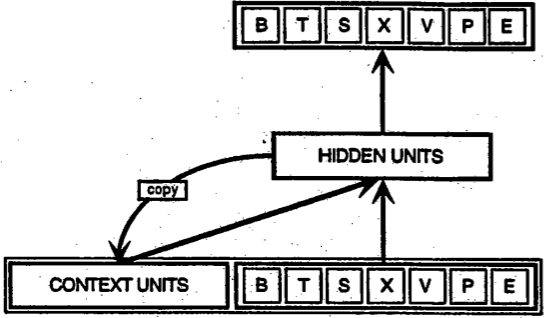
Matemáticamente
$$ h_t=\sigma(Wx_t+Uh_{t-1})\\ y_t=Vh_t $$Recurrentes
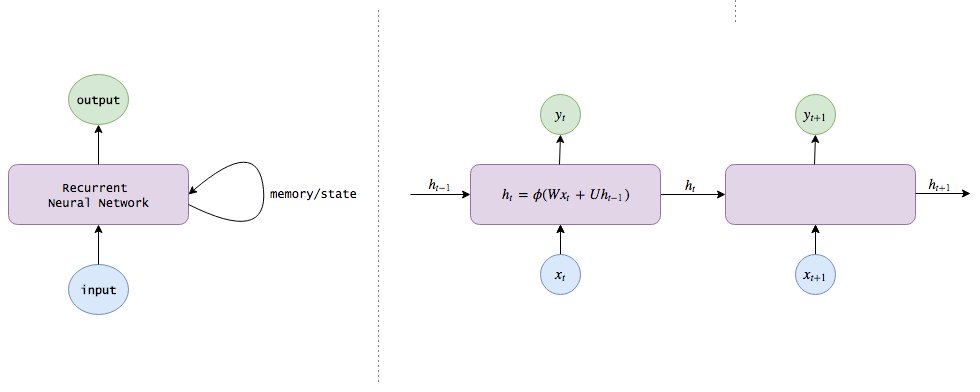
Otra forma

Problemas con recurrents
- La memoria se pierde
Redes de memoria de largo a corto plazo
Long short-term memory
- Mecanismo para recordar
- Mecanismo para olvidar
Recurrents
Reconfigurando
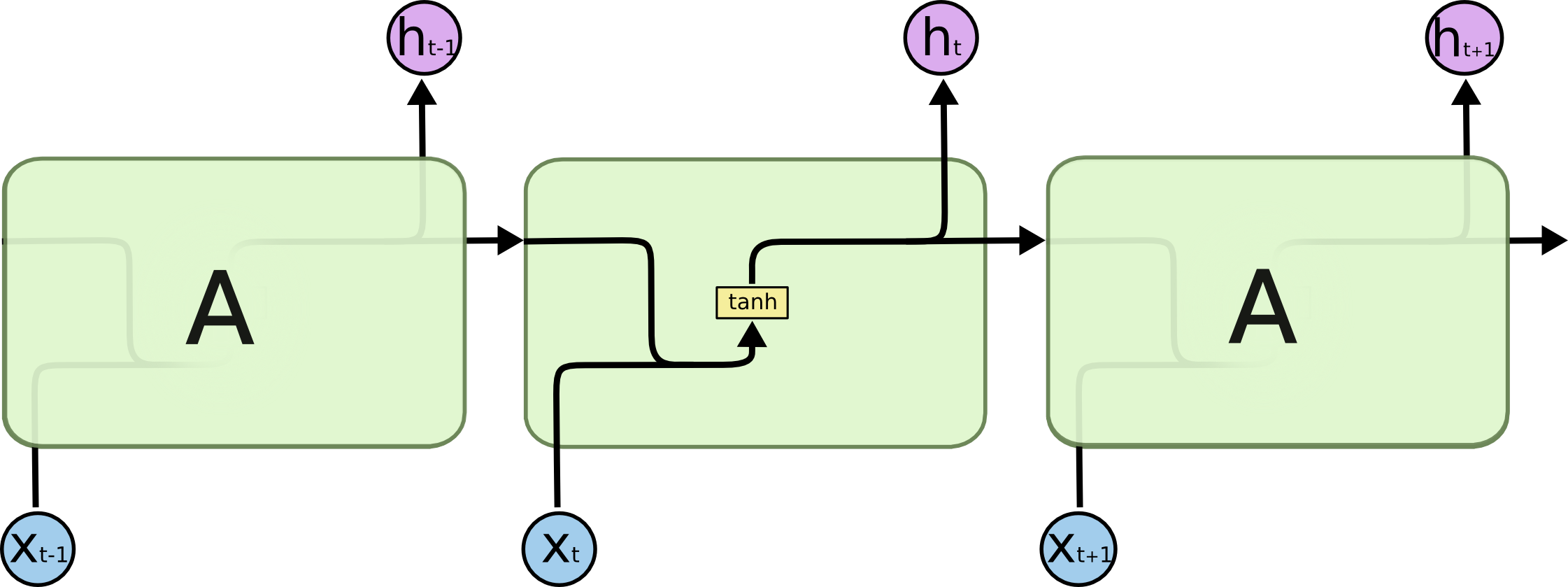 $$
h_t=\tanh(W[x_t,h_{t-1}]+b)\\
$$
$$
h_t=\tanh(W[x_t,h_{t-1}]+b)\\
$$
Otra forma
Compuerta
En una red forward que decide que info pasa y cual no
$$ \begin{pmatrix} a_1\\ a_2\\ a_3\\ a_4\\ a_5\\ \ldots\\ a_n\\ \end{pmatrix} \bigotimes \begin{pmatrix} 0\\ 1\\ 1\\ 0\\ 1\\ \ldots\\ 1\\ \end{pmatrix}= \begin{pmatrix} 0\\ a_2\\ a_3\\ 0\\ a_5\\ \ldots\\ a_n\\ \end{pmatrix} $$Compuerta
En una red forward que decide que info pasa y cual no
$$ \begin{pmatrix} a_1\\ a_2\\ a_3\\ a_4\\ a_5\\ \ldots\\ a_n\\ \end{pmatrix} \bigotimes sigmod(Wx+b) = \begin{pmatrix} 0\\ a_2\\ a_3\\ 0\\ a_5\\ \ldots\\ a_n\\ \end{pmatrix} $$LSTM
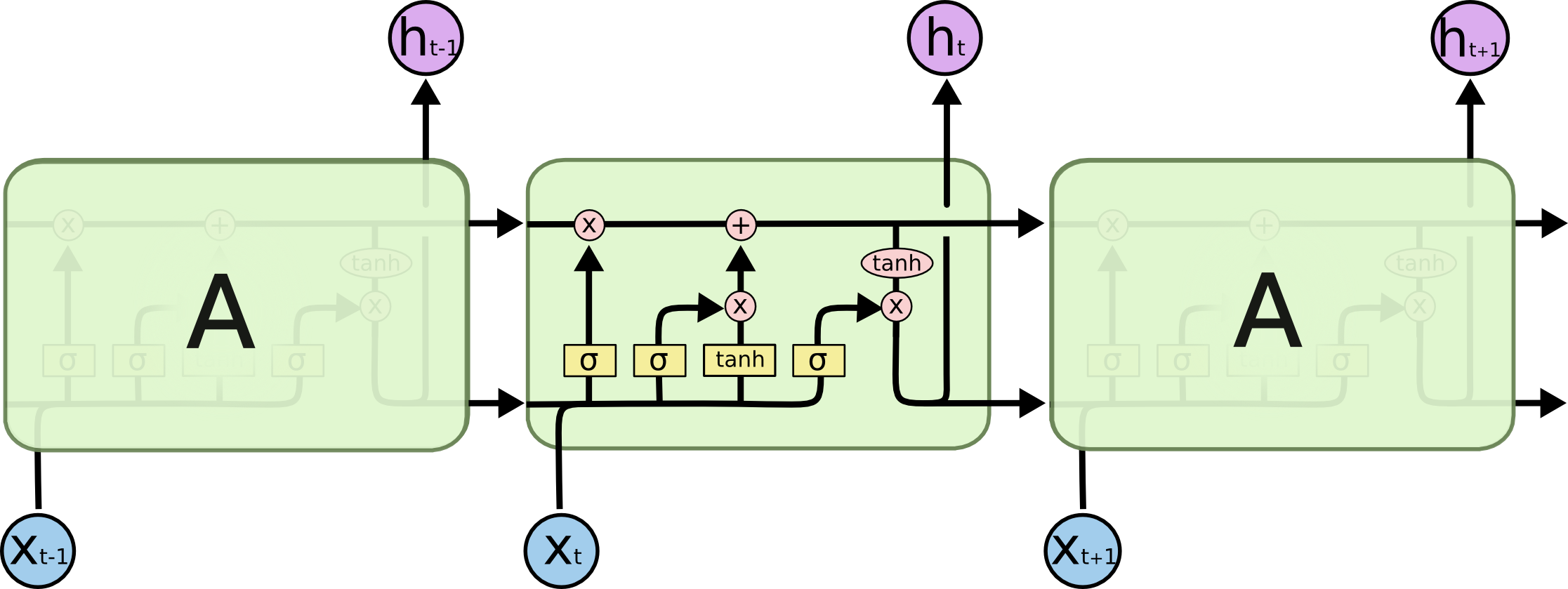
El contexto
Preferimos una activación sigmoide por cada celda del contexto: 0 olvida, 1 recuerda
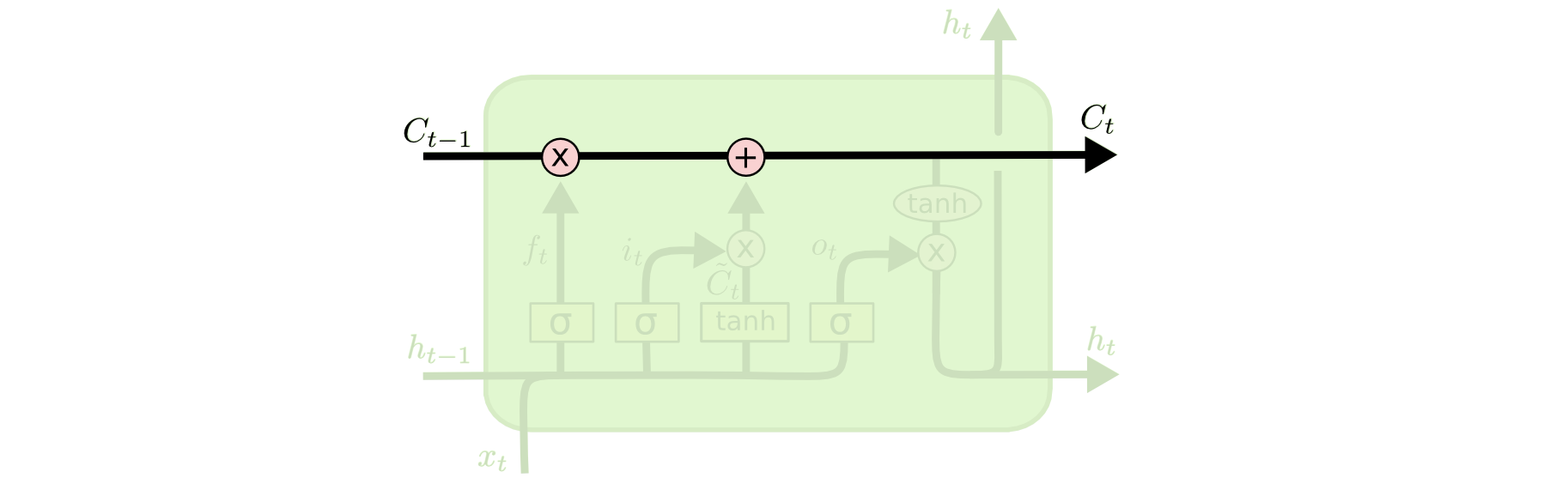
Paso 1
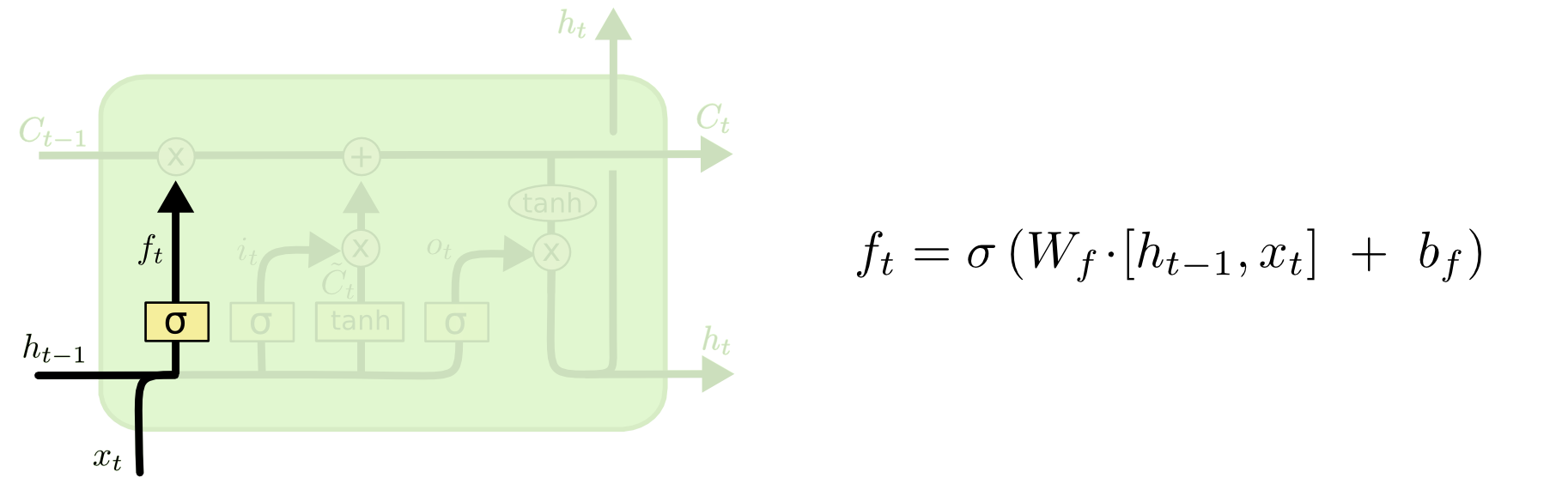
Qué tanto olvidar del contexto dada la nueva información
Paso 2
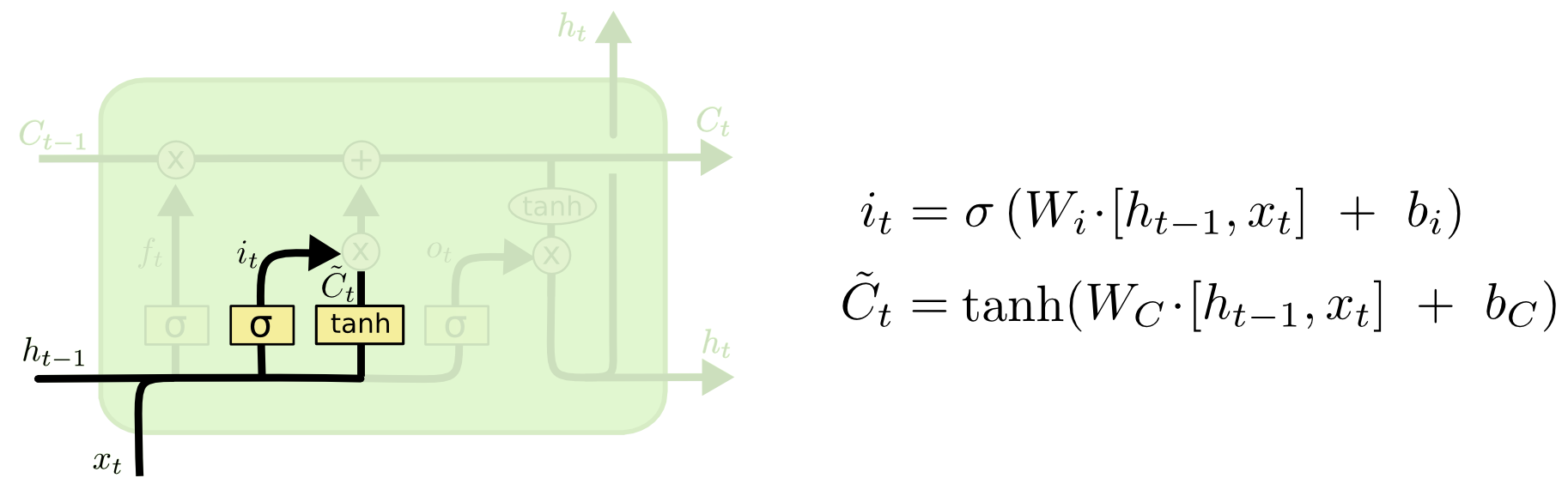
Qué tanto agregar al contexto dada la nueva información: identificar información ($i$) y crear información ($\tilde{C}$)
Paso 3
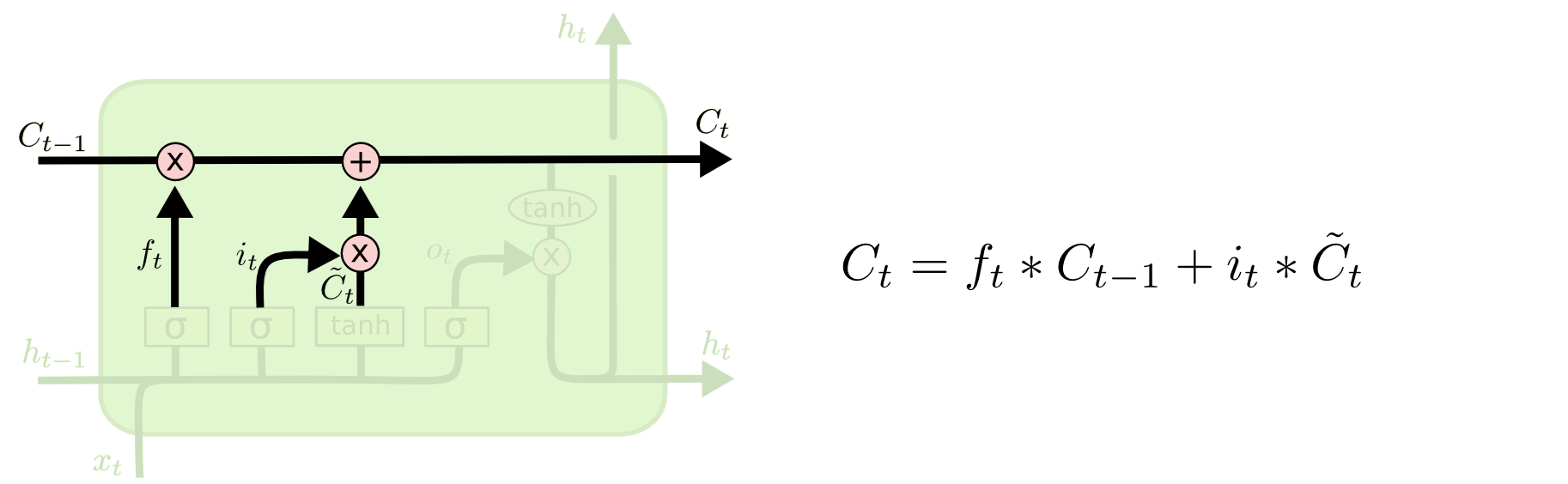
Crear contexto
Paso 4
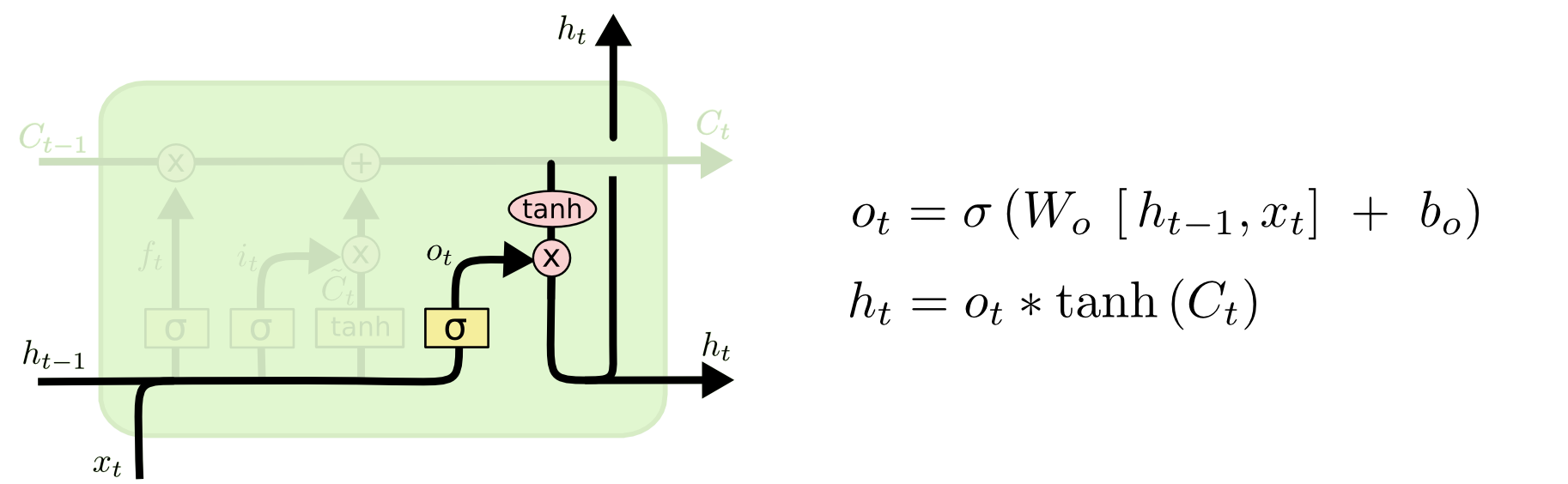
Dada la entrada qué elementos de la salida y generamos la salida con el contexto
Variante: Peephole
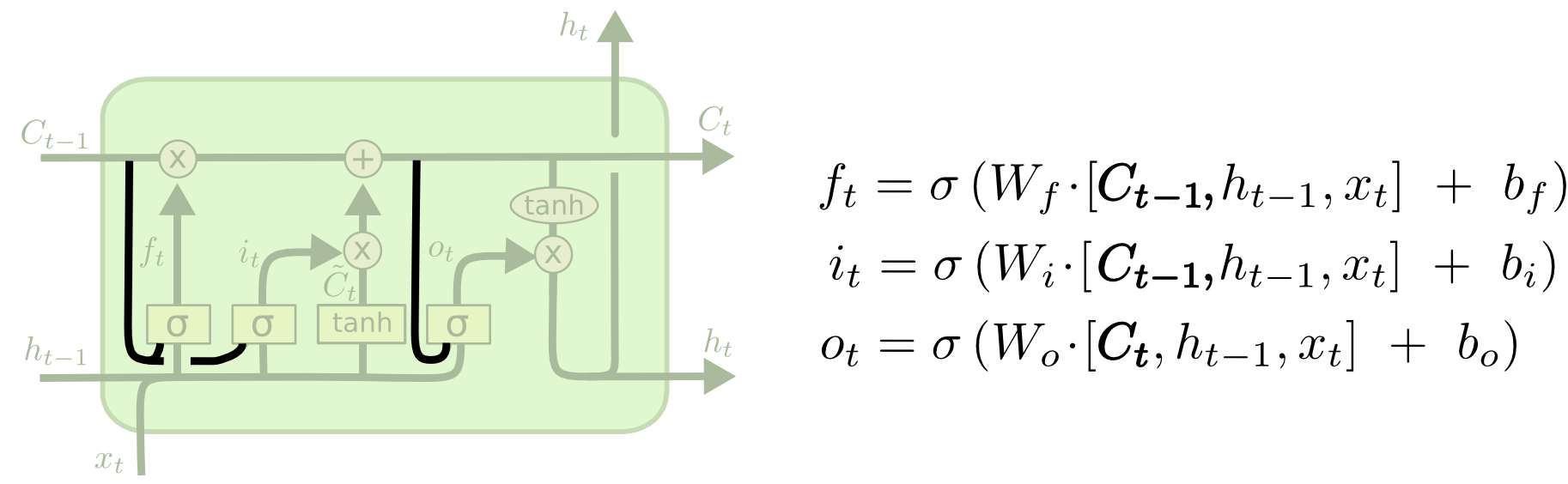
Se ve el contexto
Variante: acoplada
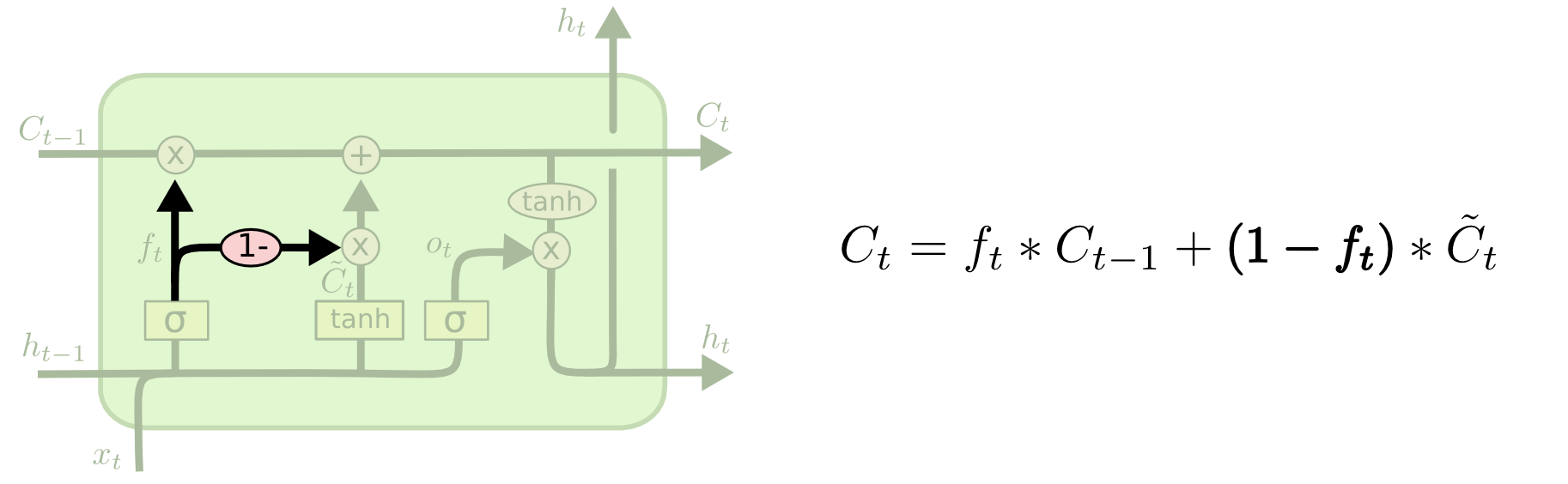
Mecanismo recuerda/olvida
Variante: Gated Recurrent Unit

Mecanismo recuerda/olvida
¿Entrenamiento?
Backpropagation through time
Celda

Parámetros
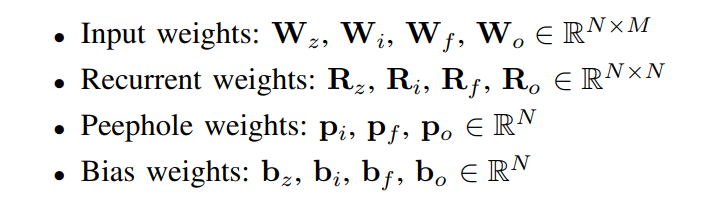
Forward passs

Backward passs
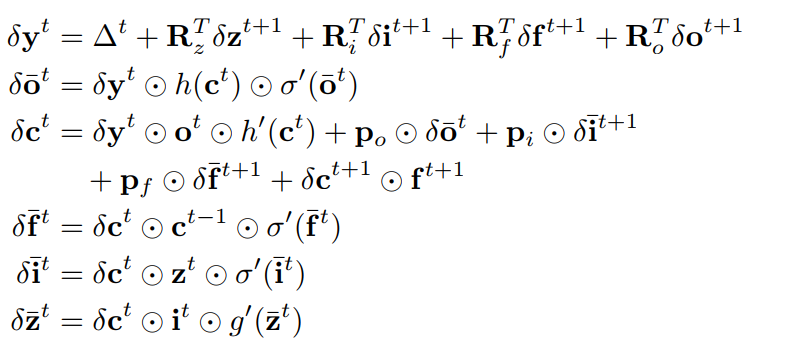
El caso de x
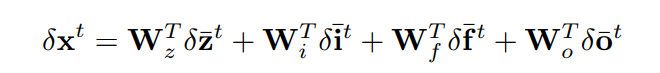
LSTM weights
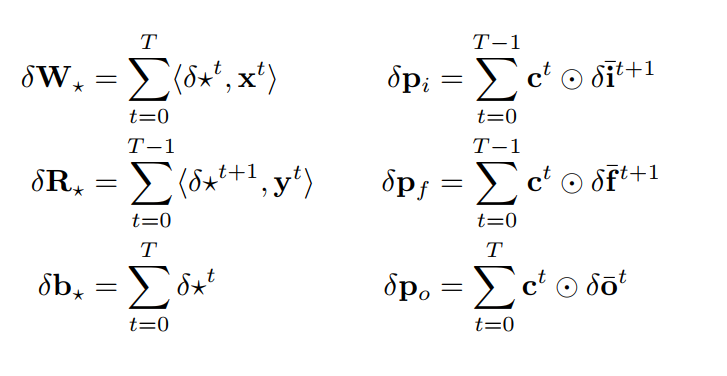
Hiperparámetros
- Número de unidades ocultas de la salida ($y$ o $h$)
- Número de unidades ocultas del contexto
- Tamaño de la secuencia
Padding
Cuando entrenamos por batch, las secuencias deben tener el mismo tamaño
- No usar batch
- Agrupar por longitudes (no random)
- Hacer padding (agregar zeros)
Dirección padding
- Agregar símbolo de inicio y final
- Agregar hacia la izquierda
- Agregar hacia la derecha
LSTM bidireccional
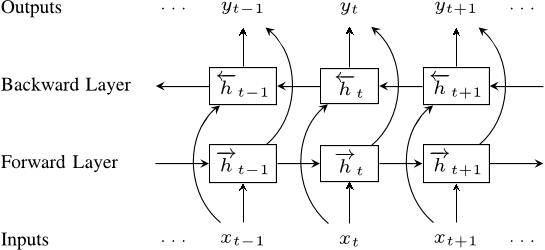
Embeddings
Para casos categóticos
- Entra una secuencia de one-hot
- Asociar a cada categoria con un vector (embedding)
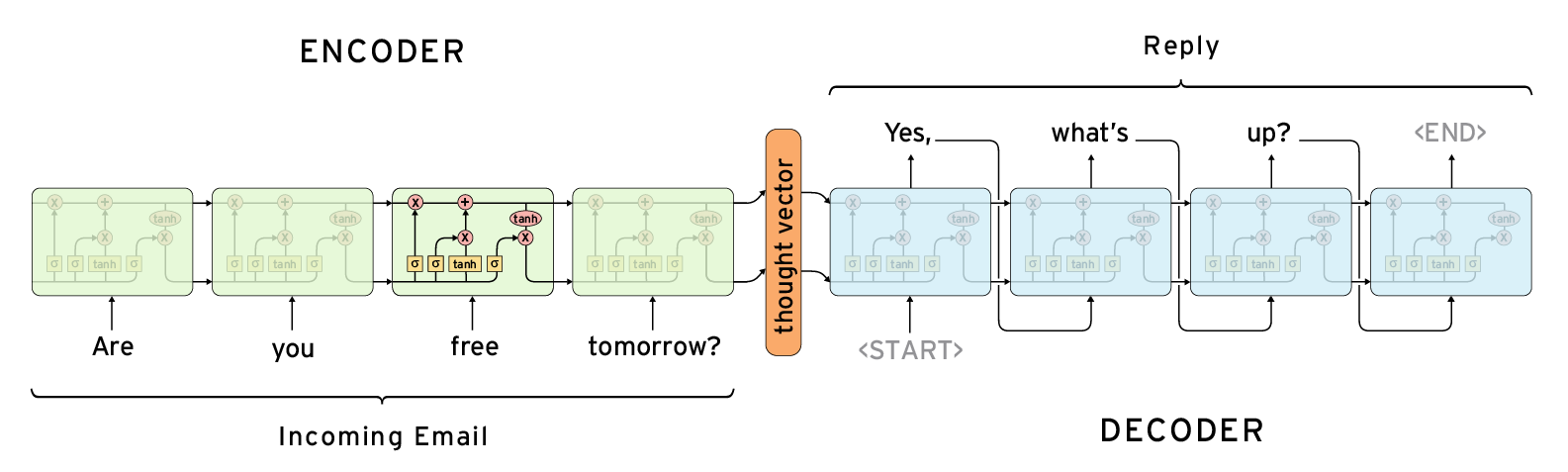
seq2seq

Chatbot

Clustering, reducción dimensional y visualización by Ivan V. Meza Ruiz is licensed under a Creative Commons Reconocimiento 4.0 Internacional License.
Creado a partir de la obra en http://turing.iimas.unam.mx/~ivanvladimir/slides/rpyaa/07_cluster.html.