
title: “Máquinas de soporte vectorial” date: 2014-07-17 page: True type: teach author: Ivan Vladimir Meza Ruiz language: es license: ccbysa summary: Introduction to Support Vector Machines
Las máquinas de soporte vectorial son una técnica de aprendizaje automático muy popular y fácil de usar con las implementaciones actuales.
Hoy en día SVM son el estado del arte para problemas de clasificación, conocemos muy bien sus ventajas y también sus limitaciones. En problemas de clasificación queremos aprender un modelo que nos permita separar ejemplos de una clase de otra clase (o de multiples clases).
Cuando nuestros ejemplos los podemos representar a través de vectores, lo más fácil para separar dos clases es utilizar una línea.

Para un nuevo ejemplo, dependerá de que lado queda de la línea para saber a que clase pertenece.
Suport Vector Machine busca una línea muy particular, esta es la línea que
maximice la distancia entre dos ejemplos de cada clase que no tengan elementos
entre ellos. Los ejemplos usados para definir esta línea se le conocen como
vectores de soporte, de ahí su nombre. Como se ilustra en la imagen.
Por supuesto las matemáticas para encontrar esa línea son intensas, pero nada del otro mundo. Por supuesto, el algoritmo escala para cuando tenemos más que dos dimensiones como en nuestro problema de detectar objetos en donde un descriptor HOG tine 900 dimensiones para imágenes de 48x48.
Más allá de las líneas
Cuando nuestro problema se puede separar usando líneas, decimos que es linealmente separable. Pero no todos los problemas lo son. En esos casos, SVM contiene un ’truco’ que es el de trasladar el problema a otra dimensión donde sí sea separable:
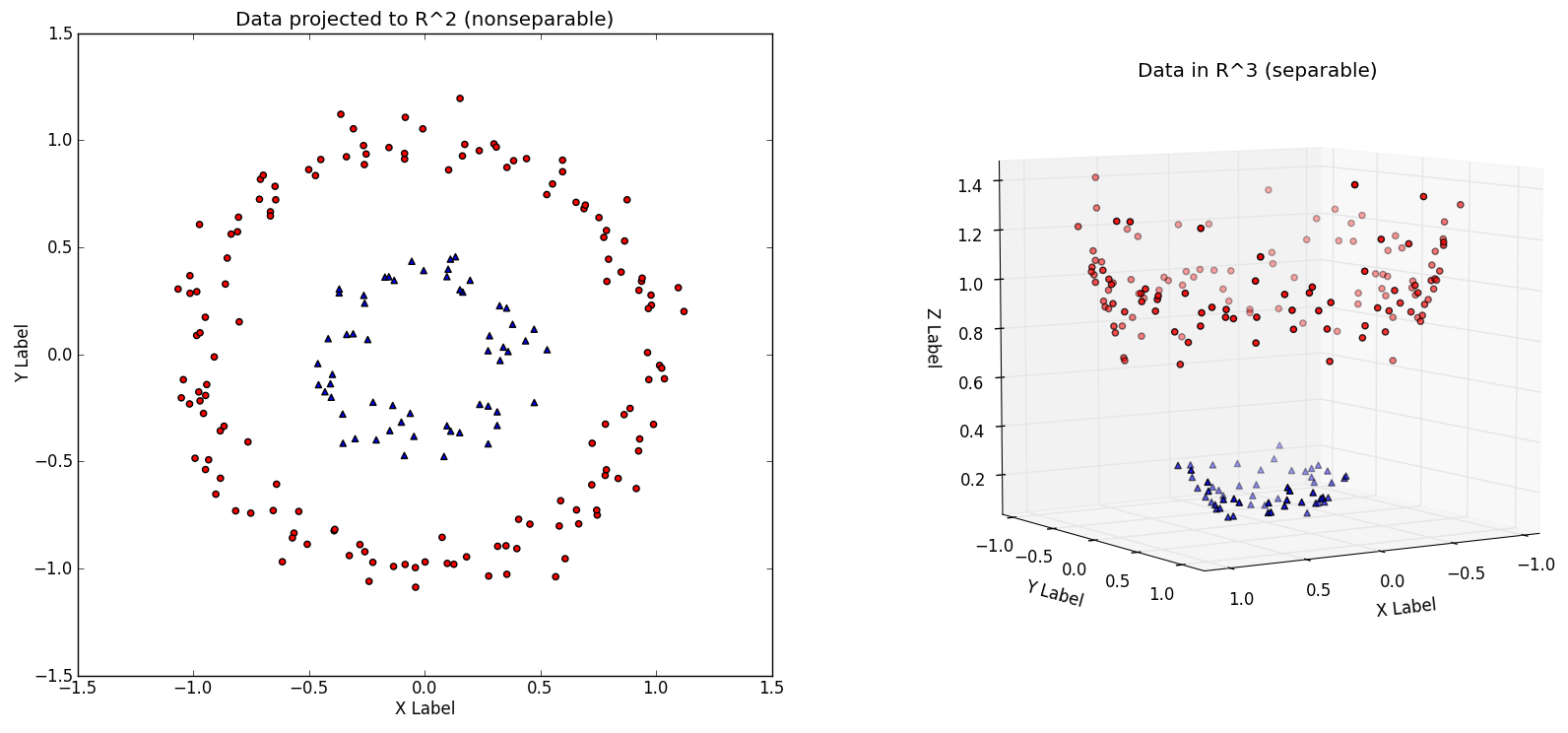
En resumen, para resolver el problema SVM puede aumentar el número de dimensiones de nuestros ejemplos. Sin embargo, esto es literalmente un truco y SVM lo maneja a través de la definición de un ‘kernel’ que transforma nuestros ejemplos. Algunos’kernels’ comunes son:
SVM y OpenCV
OpenCV incluye una implementación de SVM. Lo que necesitamos pasarle son ejemplos positivos y ejemplos negativos.
#!python
svm_params = dict( kernel_type = cv2.SVM_LINEAR,
svm_type = cv2.SVM_C_SVC,
C=2.67, gamma=5.383 )
svm = cv2.SVM()
svm.train_auto(trainData,responses,None,None,params=svm_params,k_fold=3)
La variable trainData y response representa a los ejemplos (positivos y negativos), y la variable svm_params los parámetros de nuestra máquina. En este caso le pedimos que sea una máquina con un kernel linear (SVM_LINEAR), es decir no usamos el truco inherente a SVM y confiamos que caras de no caras sean linealmente separables. Le pedimos que use la implementación de OpenCV (SVM_C_SVX), y finalmente dos parámetros del algoritmo. Sin embargo, estos últimos parámetros no tendrán un efecto, ya que usamos la versión auto en donde el sistema adicional a calcular el modelo calcula estos parámetros.
Una vez que tenemos el modelo aprendido, podemos usarlo para predecir.
!python
svm.predict(nuevo_ejemplo)
SVM para caras
Entonces para que la máquina SVM aprenda a diferenciar caras de no caras, lo que le tenemos que pasar son ejemplos de estas (positivos) y ejemplos de no caras (negativos). Para el primer caso, necesitamos recolectar una base de datos. En particular, como queremos usar el descriptor HOG necesitamos que los ejemplos estén estandarizados en tamaño. Una opción es recurrir a fotos, etiquetar donde están las caras y extraer las caras. En este caso no serán estándar por lo que tendremos que escalarlas a un tamaño definido.
Para el caso de los ejemplos negativos. Podemos usar una colección de fotos donde estemos seguros que no aparecen caras y cortar de manera aleatoria segmentos del tamaño adecuado, extraer su descriptor HOG y utilizarlo como caso negativo.
El siguiente código entrena un modelo de SVM en base a descriptores HOG de caras siguiendo esta estrategía: