
Un problema que surge inmediatamente al trabajar con archivos de audio es la gran variabilidad de los valores en el dominio de la amplitud. Por ejemplo el siguiente audio1 :
esta compuesto por una secuencia consecutiva de 984,000 valores/muestras que representan el ‘volumen’ del sonido para diferentes tiempos en la grabación. Tratar de identificar patrones en esta secuencia de valores es una tarea titánica, además que no representa la forma en como el oído humano escucha, que es en el dominio de la frecuencia en lugar en el dominio de la amplitud. Los coeficientes cepstrales en la frecuencia-Mel tratan de resolver este problema (Mel-frequency cepstral coeficients, MFCC). Para lograr esto se intercambian segmentos/ventanas de la señal original con 13 valores/coeficientes. En la práctica una configuración común es reducir 160 muestras de amplitud a 13 valores, que significa que nuestro audio original queda representado por aprox. 79,950 valores.
MFCCs no solo están motivados por su efecto en comprimir los datos, sino también tienen una motivación matemática, biológica y de procesamiento de señales. En este post explicaremos como se calculan las MFCCs y trataré de presentar algunas de las motivaciones detrás de los cálculos. Además presentaré el código detrás de cada una de los ejemplos. Para reproducir esto es necesaria la librería audioprocessing que estamos desarrollando en el Grupo Golem y que está disponible en Audio Golem .
El dominio de la frecuencia
Como su nombre lo sugiere la frecuencia tiene que ver con periodicidad, en este caso, periodicidad matemática. En términos matemáticos toda función en el tiempo puede ser representada por una combinación de funciones periódicas (estas son funciones que se repiten de manera infinita, por ejemplo una senoide). Una analogía culinaria son los ingredientes de un platillo, el platillo es la función en el tiempo y los ingredientes son las funciones periódicas; entonces dado un platillo, lo podemos representar por una combinación de sus ingredientes, que es lo que representa la receta. Las matemáticas detrás de estas ideas son muy bonitas, algo complicadas, pero también muy generosas. Creo que no tengo que explicar porque bonitas, complicadas porque originalmente la función en el tiempo tiene que ser también periódica, afortunadamente con matemáticas discretas esto no es un requisito, pero ahora en lugar de obtener una receta única obtenemos una secuencia de éstas. Y finalmente, son generosas porque nos permiten ir de amplitud a frecuencia y en reversa, cosa que no podemos hacer con nuestra analogía culinaria, una vez que preparamos la receta, muy difícilmente podemos regresar a los ingredientes originales.
Regresando a nuestra señal de audio, el dominio de la frecuencia nos va a permitir identificar que ’tonos’/frecuencias la componen; como no se trata de una función periódica, esta limitada en el tiempo, obtendremos estos ’tonos’ para diferentes segmentos de la señal de audio. Es decir, obtendremos como cambian los tonos que componen a la señal conforme avanza el tiempo. Muchos reproductores de audio hoy en día muestran esta información en formato de barras por grupos de frecuencias, es más nos dejan jugar con los límites de estas frecuencias para ecualizar el audio, pero, por el momento no vamos a hablar de ecualización.
El algoritmo
Los MFCCs van a representar a elementos en el dominio de la frecuencia, nada más que vamos a utilizar alguna de nuestra intuición fonética para poderlos reducir en número a valores muy representativos. Los pasos a seguir son los siguientes:
- Dividir la señal en ventanas del mismo tamaño (se recomienda que estén intercaladas)
- De preferencia se una ventana de Hamming por cada ventana
- Para cada ventana calcular la transformada discreta de Fourier
- Con los valores de la transformada de Fourier calcular el periodograma que representa la energía por cada valor de frecuencia.
- Filtrar las frecuencias y energías del periodograma usando un banco de filtros Mel.
- Calcular el logaritmo de la energía por cada uno de los filtros.
- Calcular la transformada coseno discreta de las energías
- Quedarse con los valores 1 a 13 de esta transformada, que representan a los 13 coeficientes MFCCs
A continuación iremos viendo cada una de las etapas. Para ilustrar estos pasos y cada uno de los puntos utilizaré los 10 primeros segundos de la grabación presentada al principio. Para preparar el ambiente para los ejemplos ejecutar:
import numpy as np
import matplotlib.pyplot as plt
import scikits.audiolab as audiolab
sndf=audiolab.Sndfile('Turdus_migratorius_Esau_Villareal.wav','r')
data=sndf.read_frames(sndf.samplerate*10)
sndf.close()
Este código guarda los primeros 10 segundos de la grabación en la variable
data, la cual podemos graficar en el tiempo de la siguiente forma:
plt.plot(data)
# Set the x axis values to seconds
plt.xticks([i*16000 for i in range(11)],["%ds"%i for i in range(11)])
plt.show()
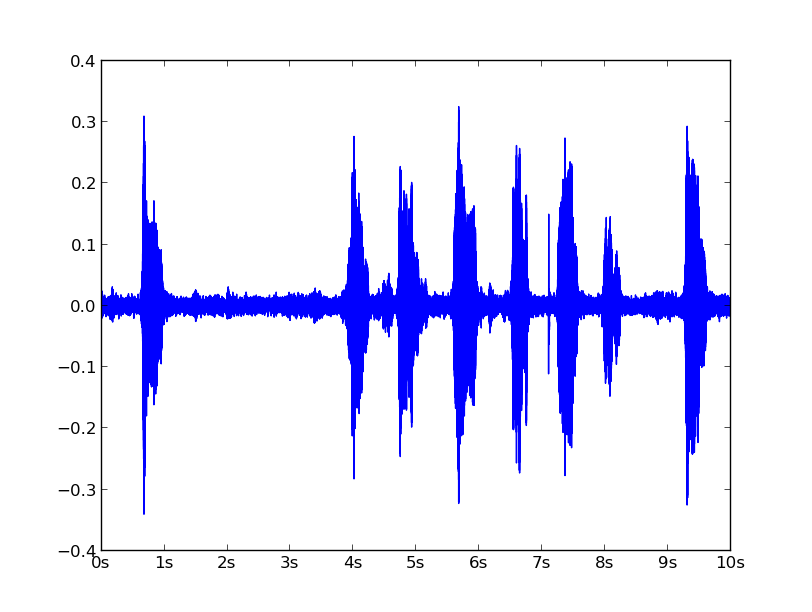
Lo que nos muestra un total de 160,000 valores por los 10 segundos de la grabación (en este caso el sample rate de la grabación es de 16000 muestras por segundo).
Ventaneo
Como habíamos establecido dado que nuestra señal de audio no es periódica no es posible calcular sus componentes en frecuencia para toda ella. Por lo que se procede calcular los componentes para segmentos de esta. A estos segmentos se le conocen como ventanas. Podemos pensar que lo que hacemos es suponer que lo que está en la ventana representa a una función periódica, por lo que podemos aplicar la matemática que nos permite saber los componentes para una función periódica.
Una vez que tenemos los componentes para una ventana nos podemos mover a la siguiente ventana en el tiempo y calcular los componentes para esa nueva ventana. De manera práctica obtendremos una secuencia de como evolucionan los componentes en el tiempo.
En este proceso hay que definir dos parámetros, el primero es el tamaño de
la ventana y el segundo la cantidad de muestras a brincar entre ventanas.
Lo que queremos es que la ventana cubra suficientes muestras de tal forma
que absorba la riqueza de componentes en frecuencia y que el brinco sea lo
suficientemente pequeño que capture un continuo en los componentes, pero
que nos permita reducir el número de muestras. Para una sample rate de
16000 los valores comunes son un tamaño de ventana de 400 y un brinco de
160 muestras entre ventanas.
El siguiente código dibuja la primera y segunda ventana de nuestra grabación de manera continua con diferentes colores.
n1=data[:400]
win2=np.zeros(560,'double')
win2[160:560]=data[160:560]
plt.plot(win1)
plt.plot(win2)
plt.show()
Como pueden observar ambas ventanas se sobre imponen y de hecho comparten valores entre sí, del 160 al 400.
Hamming
La ventana Hamming nos ayuda ha hacer smooth la información en la ventana de la señal original, esto ayudará a filtrar frecuencias espurias que aparecen por cortar abruptamente la señal. La siguiente figura muestra la ventana Hamming, una ventana de nuestra señal y la señal después de pasarla por la ventana Hamming:
ham=np.hamming(400)
win=data[64000:64400]
f,ax=plt.subplots(3)
ax[0].plot(ham)
ax[1].plot(win)
ax[2].plot(win*ham)
f.show()

Transformada Discreta de Fourier
La transformada discreta de Fourier es la operación que nos permite calcular los componentes en el dominio de la frecuencia. Desafortunadamente, la transformada nos da componentes en el dominio de los números imaginarios, que son los que utilizamos para representar información sobre la amplitud de las funciones periódicas por grupos de frecuencias. Sin embargo en lo que estamos interesados es en la energía en esas frecuencias, por lo que elevamos al cuadrado la información real e imaginaría para extraer la magnitud de la energía. Con esta información, podemos sacar el periodograma para esa ventana de la siguiente forma:
s=np.fft.rfft(win*ham,512)
p=(s.real**2+s.imag**2)/len(win)
plt.plot(p)
plt.show()
Como vemos primero se calcula la transformada de Fourier rápida para números reales y luego se eleva al cuadrado tanto la parte real como imaginaría y se normaliza por el tamaño de la ventana. En particular se pide que la frecuencias se alojen en 512 recipientes/bins, pudimos elegir algo más granular pero 512 es común en aplicaciones de voz. Este código resulta en la figura:

Vemos que esta particular ventana tiene componentes alrededor de los recipientes número 85. Además vemos que el tamaño de las frecuencias es menor a 512, de hecho es la mitad, esto porque los valores son simétricos y representan frecuencias negativas, por lo que podemos obviar esos valores. Ahora si calculamos cada uno de los periodogramas para todas las ventanas en nuestra señal y la graficamos con respecto al tiempo se obtiene la siguiente figura:

Lo que vemos es que altas frecuencias no hay mucha información, pero sí a bajas. También hay que notar que podemos describir toda nuestra señal ahora con 257,000 valores. Es decir, el número de valores aumento de 160,000 para los diez segundos, por lo que vamos a necesitar filtrar algunos de estos valores.
Filtros Mel
Un filtro Mel es un filtro triangular que ayuda a obtener información de una banda de frecuencia. Estas bandas están basadas en la percepción del oído humano, en donde frecuencias bajas son más granulares y con mayor peso y frecuencias altas más amplias pero con menor pes pero con menor peso. La siguiente figura muestra las bandas para nuestras 257 recipientes de frecuencias:
from golemaudio.audiofun import mel
plt.plot(mel.MELfilterbank_speech)
plt.show()

Como se puede apreciar un filtro MEL se concentra en las frecuencias bajas
y abarca pocas frecuencias, conforme crece las frecuencias comienza
abarcar más frecuencias pero la altura del filtro disminuye. Esta forma de los
filtros tienen que ver como percibimos el volumen en frecuencias altas contra
el volumen en frecuencias bajas. En el ejemplo se presentan un total de 26
filtros/bandas. Cada filtro se va a utilizar para concentrar las energías en
la banda en un solo valor, de esta forma después de aplicar el filtro
obtendremos 26 valores. Pero además vamos a modificar la escala de la energía
por una logarítmica que nos va a alizar los valores y hacer más manejables.
Adelante se muestra el efecto de este proceso en una ventana de la señal.
f,ax=plt.subplots(3)
ax[0].plot(p)
ax[1].plot(np.dot(p,mel.MELfilterbank_speech).clip(1e-5,np.inf))
ax[2].plot(np.log(np.dot(p,mel.MELfilterbank_speech).clip(1e-5,np.inf)))
f.show()

Podemos hacer este cáculo para todos los periodogramas de nuestra señal, lo que nos da la siguiente figura:

Hay que notar, que el número de valores se redujo de 257,000 a 26,000. Para una mejor comparación dibujamos para el primer segundo de audio de el periodograma y de los coeficientes Mel.
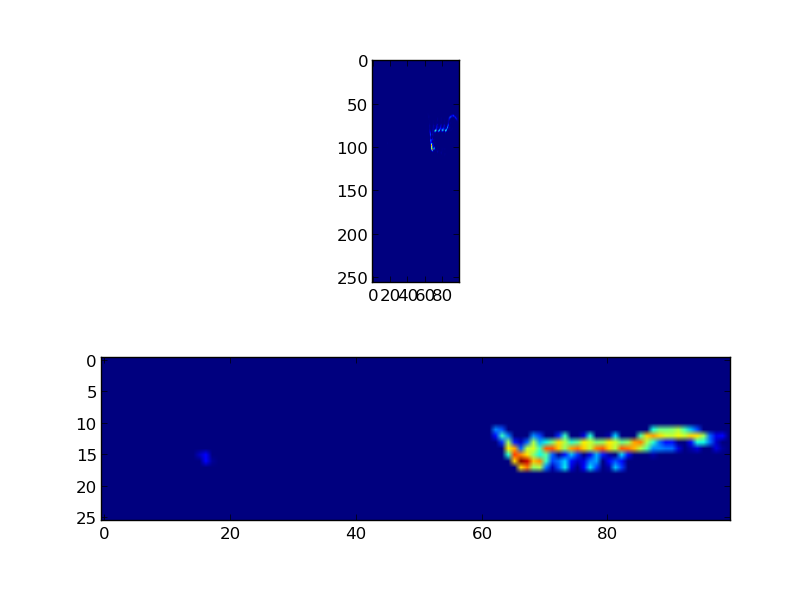
Transformada coseno discreta
De hecho es la escala log del la energía de los coeficientes MEL lo que convierte a esta señal en un coeficiente cepstral. El prefijo “ceps” es el inverso de “spec” (de espectral) y lo que señala es que podemos tratar dicha señal como si fuera una señal en amplitud. Por eso, el siguiente paso es aplicar una transformada de coseno a las coeficientes MEL. La intuición desde paso es desde el punto de vista de procesamiento de señales, que nos va a permitir comprimir dicha señal en elementos más informativos. De hecho de años de experiencia en el campo de reconocimiento de voz, de esta transformada coseno nada más vamos a conservar del segundo al treceavo valor, el resto es ignorado. El siguiente código calcula esta compresión para una ventana, compara la escala log de los coeficiente Mel con los MFFCs para esa ventana :
from scipy.fftpack import dct
mlog=np.log(np.dot(p,mel.MELfilterbank_speech).clip(1e-5,np.inf))
f,ax=plt.subplots(2)
ax[0].plot(mlog)
ax[1].plot(d)
f.show()

Finalmente, podemos calcular las MFCCs para todas las ventanas de audio, el resultado es el siguiente para el primer segundo de la grabación:

Notas finales
De esta forma es posible calcular los MFCCs para una señal. En resumen el procedimiento fue: por ventana, identificar la energía para los componentes en el dominio de la frecuencia, filtrar estos componentes con un modelo de la percepción humana y comprimir estos valores aun más. Los coeficientes resultantes pueden ser utilizados para tareas de aprendizaje automático en donde se les denominará como los features/características de la señal.
Agradezco a Esaú Villareal por facilitarnos acceso a su grabación del ave Turdus Migratorius.
Referencias
- Tutorial Mel Frequency Cepstral Coefficient
- Implementación de MFCC basada en tutorial
- Implementación alternativa de MFCC basada en Sphinx
- Otra implementación en python
- Otra implementación en Octave/Matlab
- Ventana de Hamming
- Transformada de Fourier
- Transformada discreta de Fourier
- Transformada Rápida de Fourier
- Periodograma
- Escala de Mel
- Banco de filtros Mel
- Cepstrum de frecuencia-Mel
- Escala logarítmica
- Transformada discreta de coseno
- Coeficientes de Cepstrum de frecuencia-Mel
1 Grabación del ave turdus migratorious hecha por Esaú Villareal como parte de su tesis de licencitura en la Ciudad de México.